机器人应用中涉及到的核心技术包括:环境感知与理解、实时定位与建图、路径规划、行为控制等。GOAT通过多模态结合终生学习的方式让你的机器人可以在未知环境中搜索和导航到任何物体。小白也可以零门槛上手。
项目地址:https://theophilegervet.github.io/projects/goat/
论文地址:https://arxiv.org/pdf/2311.06430.pdf
GOAT是一种通用导航系统,具有多模态、终身学习和平台无关的特点。它通过模块化系统设计和实例感知的语义记忆实现,可以识别不同类别的物体实例,从而实现通过图像和语言描述导航到目标。在实验中,GOAT在9个不同的家庭中执行了675个目标,成功率达到83%,比之前的方法提高了32%。GOAT还可以应用于拾取和社交导航等下游任务。
本文介绍了一个受动物和人类导航研究启发的移动机器人系统。动物和人类都会维护内部空间表示,这需要机器人具备认知地图。机器人需要通过“终点、起点、途经点”等方式学习路线知识,不断完善内部空间表示。此外,机器人需要维护丰富的多模态空间环境表示,因为地标的视觉外观在导航中起着重要作用。
一个机器人在未知环境中进行导航和目标定位的过程。机器人需要通过视觉和语义理解来识别目标物体,并在环境中建立和更新记忆。同时,机器人还需要有效的规划和控制来避开障碍物,达到目标位置。

GOAT通用导航系统,具有多模态、终身学习和平台无关等特点。GOAT通过设计一个实例感知的语义记忆来实现,可以区分同一类别的不同实例,从而实现对图像和语言描述的目标导航。该记忆会随着代理在环境中的时间不断增强,从而提高目标导航的效率。GOAT可以无缝地部署在不同机器人上,本文在四足和轮式机器人上进行了实验。
在一系列实验中,GOAT在9个不同的家庭环境中进行了超过90小时的比较,选择了675个目标,并跨越200多个不同的物体实例。结果显示,GOAT的整体成功率达到了83%,比之前的方法和消融实验提高了32%。GOAT的性能随着在环境中的经验而提高,从第一个目标的60%成功率提高到完全探索环境后的90%成功率。此外,我们还证明了GOAT作为一种通用导航原语,可以轻松应用于拾取放置和社交导航等下游任务。GOAT的性能部分归功于系统的模块化特性:它利用了在所需的组件中的学习(例如物体检测、图像/语言匹配),同时还利用了强大的经典方法(例如映射和规划)。模块化还有助于在不同的机器人实体和下游应用中轻松部署,因为可以轻松适应个别组件或引入新的组件。
GOAT是一个多模态、终身学习的导航系统,能够在现实世界中处理多个目标规范。它超越了以往只在一个方面进行创新的方法,如只处理对象目标或图像目标。GOAT在现实世界中展示了多个目标规范的结果,这是以前的方法所没有的。
GOAT是一种基于动物和人类导航的机器人,它通过维护环境地图和视觉地标来实现导航。它使用实例感知的对象记忆来存储视觉地标,并支持图像和自然语言查询。为了实现这一点,它使用了CLIP和SuperGlue等技术。GOAT的记忆表示结合了参数化和非参数化表示的优点,既可以建立语义地图,也可以存储原始图像。
GOAT在Boston Dynamics Spot和Hello Robot Stretch机器人上进行了定性实验,并在Spot机器人上进行了大规模定量实验。实验结果总结在视频1中。实验涉及了9个真实家庭和200多个不同的物体实例。

去任何事情:多模式导航的终身学习
任务要求机器人在未知环境中到达一系列未知目标物体,机器人每个时间步接收到RGB图像、深度图像和姿态读数等观测信息,以及当前目标物体的类别和唯一标识符。机器人需要在有限时间内尽可能高效地到达目标物体,如果机器人已经观察到下一个目标物体,则可以利用记忆更有效地导航。
在看不见的自然环境中的导航性能
GOAT代理。GOAT系统是一个能够处理多模态对象实例的智能代理。它通过感知系统处理RGB-D相机输入来检测对象实例,并将它们定位到场景的顶视语义地图中。GOAT还维护一个对象实例内存,用于定位地图中的对象实例并存储每个实例被观察到的图像。当代理接收到新的目标时,全局策略首先搜索对象实例内存,看是否已经观察到了目标。如果找到实例,其在地图中的位置将被用作长期导航目标。如果没有找到实例,全局策略将输出一个探索目标。最后,本地策略计算朝着长期目标的动作。
实例匹配策略。匹配模块使用不同的设计选择来识别对象实例内存中的目标对象实例。具体的匹配策略包括:使用CLIP特征的余弦相似度分数来匹配语言目标描述和内存中的对象视图,使用SuperGLUE进行基于关键点的图像匹配,将对象视图表示为带有一些填充的边界框以包含额外的上下文,仅将目标与相同对象类别的实例进行匹配,将目标与所有视图中匹配分数最高的实例进行匹配。
实验设置。本实验在9个视觉多样的家庭环境中评估了GOAT代理和三个基准模型。每个家庭有10个剧集,每个剧集由5-10个随机选择的物体实例组成,总共有200多个不同的物体实例。选择了15个不同的物体类别作为目标,并按照Krantz等人的协议拍摄了目标图像,并注释了3个唯一标识物体的语言描述。为了生成一个剧集,从所有可用的物体实例中随机选择一个包含语言、图像和类别目标的目标序列。评估方法包括达到目标的成功率和SPL(路径效率)。将评估指标按目标在剧集中进行报告。
基线。GOAT与三个基准模型进行比较:1. CLIP on Wheels – 与GOAT问题设置最接近的现有工作,通过匹配目标图像或语言描述的CLIP特征与内存中所有图像的CLIP特征来判断机器人是否已经看到过目标对象;2. GOAT w/o Instances – 将所有目标视为物体类别的消融模型,即始终导航到正确类别的最近物体,而不区分同一类别的不同实例,以此来量化GOAT实例感知的好处;3. GOAT w/o Memory – 在每个目标后重置语义地图和物体实例内存,以此来量化GOAT终身记忆的好处。
定量结果。GOAT取得了83%的平均成功率。与CLIP on Wheels相比,GOAT的成功率更高。实验结果表明,保持足够的信息在记忆中以区分不同的对象实例是必要的。GOAT的性能随着在环境中的经验而提高,而没有记忆的GOAT则没有提高。

定性结果。GOAT、CLIP on Wheels和没有记忆的GOAT在相同的序列中展示了性能。CLIP on Wheels在匹配图像或语言目标时会计算整个观察帧的特征,这导致匹配阈值难以调整,出现更多的误报和漏报。没有记忆的GOAT会继续重新探索先前看到的区域,并且匹配性能较差,因为代理忘记了先前观察到的实例。完整的GOAT系统可以处理这些问题,能够正确匹配所有实例并有效地导航到它们。

应用
GOAT策略可以很容易地应用于下游任务,例如拾取和放置以及社交导航。
开放场景移动操作。在移动机器人的任何部署场景中,执行重排任务的能力是必不可少的。这些命令如“把我的咖啡杯从咖啡桌上拿起来,放到洗手池”,要求代理搜索并导航到一个对象,拿起它,搜索并导航到一个容器,然后把对象放在容器上。GOAT导航策略可以很容易地与拾取和放置技能结合起来来完成这些请求。我们在30个这样的查询中评估了这种能力,这些查询涉及3个不同家庭的图像/语言/类别对象和容器。GOAT找到物体和容器的成功率分别为79%和87%。

我们在图5 (A)中可视化了一个这样的轨迹。代理的任务是首先找到一张床,找到一个特定的玩具,然后将玩具移动到床上。我们看到,在探索床的过程中,智能体观察玩具并将其保存在实例内存中。因此,在找到床后,代理能够直接导航回玩具(列2),然后有效地捡起它,并将其移回床(列5)。
社交导航。为了在人类环境中工作,移动机器人需要能够将人视为动态障碍,围绕他们进行规划,并搜索和跟踪人。为了给GOAT策略提供这样的技能,我们将人视为具有PERSON类别的图像对象实例。这使得GOAT能够处理多个人,就像它可以处理任何对象类别的多个实例一样。然后,GOAT可以在某人移动后从地图上删除他们之前的位置。为了评估将人视为动态障碍的能力,我们在5个轨迹中引入移动的人,否则遵循与我们的主要实验相同的实验设置。GOAT保留了81%的成功率。通过在5个额外的轨迹中引入这些目标,我们进一步评估了GOAT搜索和跟踪人的能力。GOAT定位和跟踪人的成功率为83%,接近静态图像实例目标86%的成功率。
我们在图5 (B)中可视化了一个轨迹的定性例子。在这里,智能体必须导航到冰箱,然后跟随人类。我们看到智能体识别了冰箱(第1列),但那里的路线被人类挡住了,所以智能体必须绕道而行(第2列)。在到达冰箱后,智能体开始跟随人类,同时根据新的传感器观察不断更新地图。这允许代理通过之前被标记为被人占用的空间(第4列)。导航目标在人在公寓周围移动时继续跟踪人(第5列)。
讨论

模块化使GOAT能够在现实世界中实现鲁棒的通用导航。GOAT系统是一个具有鲁棒性的导航平台,其模块化设计使得学习可以应用于需要的组件,同时利用强大的经典方法,可以轻松适应不同的机器人实体和下游应用。
探索过程中的匹配性能落后于探索后的性能。在探索过程中,目标到对象匹配的性能落后于探索后的性能,因为在探索过程中,刚性阈值可能会忽略真正的正例,而在探索后,代理可以选择具有最佳匹配分数的实例作为目标。
图像目标匹配比语言目标匹配更可靠。因为图像关键点匹配可以利用预测实例和目标对象之间的几何属性的对应关系。
通过分类子采样和添加上下文改进目标匹配。通过对类别进行子采样和添加上下文,可以提高目标匹配的准确性,同时减少计算量。
现实世界的开放场景检测:限制和机会。尽管开放词汇视觉和语言模型(VLM)的性能不断提高,但其性能仍然明显低于2017年的Mask RCNN模型。这可能是因为开放词汇模型在鲁棒性和多功能性之间进行了权衡,而且用于训练现代VLM的互联网规模弱标记数据源未能充分代表真实世界环境中的交互数据。
方法
GOAT系统架构
GOAT系统概述:GOAT系统包括感知系统和全局策略。感知系统通过检测物体实例并在场景的自上而下的语义地图中进行定位,将每个实例在对象实例内存中的图像存储起来。当指定一个新的目标时,全局策略首先尝试在对象实例内存中定位目标。如果没有定位到实例,则全局策略输出一个探索目标。最后,本地策略计算朝着长期目标的动作。

感知系统:感知系统接收当前深度图像Dt、RGB图像It和来自机载传感器的姿态读数xt作为输入。它使用现成的模型对RGB图像中的实例进行分割。我们使用了在MS-COCO上预训练的MaskRCNN模型,它具有ResNet50骨干网络,用于目标检测和实例分割。我们选择了MaskRCNN作为当前的开放集模型,因为在早期实验中,其他模型如Detic在常见类别上的可靠性较低。我们还估计深度以填补原始传感器读数中的反射物体的空洞。
为了填补深度图像中的空洞,我们首先使用单目深度估计模型从It中获取密集的深度估计(我们使用了MiDaS模型,但任何深度估计模型都适用)。由于深度估计模型通常预测相对距离而不是绝对距离,我们使用来自Dt的已知真实深度值来校准预测的深度。具体来说,我们求解最小化所有有深度读数的像素上估计深度和感知深度之间均方误
语义映射表示:语义地图是一个K×M×M的矩阵,其中K是地图通道数,M是地图大小,每个单元格对应物理世界中的25平方厘米。前C个通道存储物体的唯一实例ID,其余通道表示障碍、探索区域和代理的当前和过去位置。
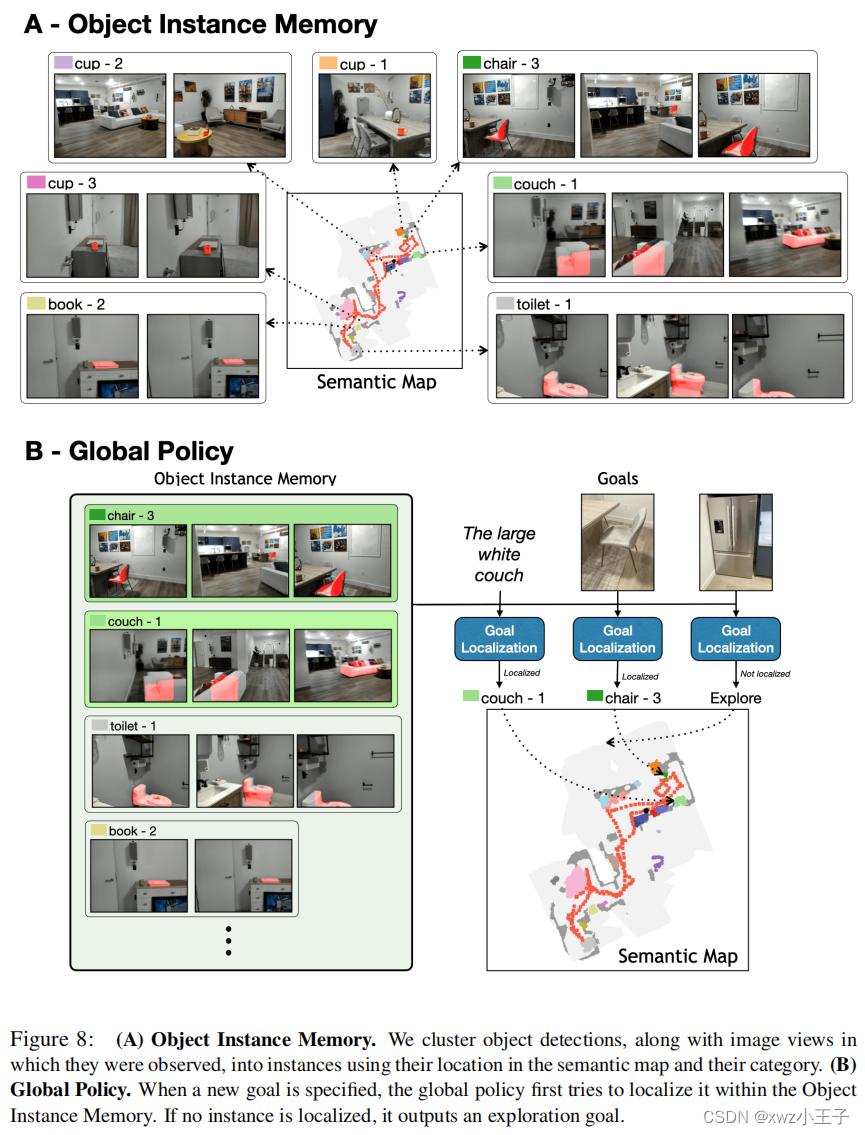
物体实例记忆:将物体检测结果按位置和类别聚类成实例。每个对象实例都由一组细胞存储在地图C中,这些细胞是由边界框和上下文M表示的对象视图组成,并且还有一个表示语义类别的整数Si。对于每个传入的RGB图像I,我们检测对象。对于每个检测d,我们使用检测周围的边界框Id,语义类别Sd,以及基于投影深度的地图Cd中的相应点。我们通过将地图Cd上的每个实例进行p个单位的膨胀来获得每个实例的膨胀点集Dd,该集合用于与先前添加到内存和地图中的实例进行匹配。我们在每个检测和每个现有对象实例之间进行成对匹配。如果语义类别相同,并且地图中的投影位置有重叠,即Sd = Si且Dd∩Ci≠∅,则认为检测d和实例i匹配。如果有匹配,我们使用新的点和新的图像更新现有实例:
否则,使用Cd和Id添加一个新实例。这个过程随着时间的推移聚合了唯一的对象实例,可以轻松地将新目标与特定实例或类别的所有图像进行匹配。
全局策略:图8 (B)展示了全局策略的流程。当给定一个新的目标时,全局策略首先在对象实例内存中搜索目标是否已经被观察到。匹配的方法根据目标的模态性进行定制。对于类别目标,我们只需检查语义地图中是否存在该类别的任何对象。对于语言目标,我们首先从语言描述中提取对象类别,然后将语言描述的CLIP特征与推断类别的每个对象实例的CLIP特征进行匹配。对于图像目标,我们首先使用MaskRCNN从图像中提取对象类别,然后使用现成的SuperGlue模型将目标图像的关键点与推断类别的每个对象实例的关键点进行匹配。在探索环境时,如果匹配分数高于某个阈值(CLIP为0.28,Superglue为6.0),则认为对象实例匹配目标;当环境完全探索时,选择相似度得分最高的对象实例。选择实例后,将其在自顶向下地图中存储的位置用作长期点导航目标。如果没有定位到实例,则全局策略输出一个探索目标。我们使用基于边界的探索方法[60],选择最近的未探索区域作为目标。
局部策略:根据全局策略输出的长期目标,使用快速行进方法规划到达目标的路径。在Spot机器人上,我们使用内置的点导航控制器来到达路径上的航点。在没有内置控制器的Stretch机器人上,我们以确定性的方式规划路径上的第一个低级动作,就像[19]中一样。
实验方法
硬件平台。GOAT导航策略与硬件平台无关,可以在不同的机器人硬件上使用。作者在9个真实家庭环境中进行了大规模的定量实验,使用了Boston Dynamics Spot和Hello Robot Stretch机器人,并与3个基线进行了比较。
在未知场景中的导航性能。我们还在9个未知的租赁房屋中进行了GOAT的“野外”导航性能评估,评估了15个不同的物体类别。
指标。我们报告了每个目标的导航成功率和路径长度加权成功率(SPL)。
补充
实例匹配策略的离线比较
我们比较了全局策略匹配模块的设计选择,该模块的作用是在先前看到的物体实例中识别目标物体实例。这个模块非常重要,因为它决定了物体实例记忆的形式,并允许GOAT agent进行多模态导航的终身学习。我们的匹配模块首先通过目标类别对实例进行筛选,并使用每个实例视图的裁剪版本,包括物体周围的一些上下文。然后,我们通过“max”操作对视图中的分数进行聚合。在探索过程中,我们对图像-图像SuperGLUE匹配使用3.0的阈值,对语言-图像CLIP匹配使用0.75的阈值。在探索后,我们选择最佳匹配实例而不使用任何阈值。

我们手动注释了每个房屋的3个轨迹,每个目标对应一个地面实例,总共有27个轨迹。这使我们能够评估不同设计选择对匹配成功率的影响:正确匹配的目标的百分比。表2呈现了以下设计选择的消融实验结果:
匹配方法。通过在对象实例内存中存储原始图像视图,我们可以使用不同的匹配方法来匹配不同的目标模态。对于语言目标描述,我们使用它们的CLIP特征之间的余弦相似度得分来匹配内存中的对象视图。对于图像目标和对象视图的匹配,我们使用SuperGLUE的CLIP特征匹配和基于关键点的匹配来评估。
匹配阈值。匹配阈值是成功匹配得分的阈值。我们使用固定的非零阈值(最佳超参数)和零阈值来展示结果。前者用于代理仍在探索场景的情况下,因为它必须决定当前观察中的实例是否与目标匹配或继续探索,后者用于代理已经探索了整个场景并始终导航到最佳匹配的情况。注意,我们假设匹配总是存在的。因此,当代理完全探索环境时,我们期望最佳匹配是正确的,假设代理检测到了对象。
实例子采样。实例子采样是将目标与迄今为止捕获的所有实例的视图进行比较,还是仅与目标类别的实例进行比较。直观地说,后者速度更快,精度更高,但可能召回率较低,因为它依赖于准确的对象检测。
上下文。匹配时使用的实例视图上下文:(i)仅检测到的实例的边界框裁剪(“bbox”),(ii)添加一些周围的上下文(“bbox+pad”),或(iii)实例所在的完整图像(“full image”)。
最佳匹配选择标准。当用一个目标比较多个实例的多个视图时,我们可以通过以下方式选择最佳匹配:(i) max:选择具有最大匹配分数的实例(从任何一个视图中),(ii) median:最高的中位数匹配分数(在所有视图中),(iii)最高的平均匹配分数(在所有视图中),以及(iv)在top–k个视图中最高的平均分数。
从表2的图像到图像匹配部分可以看出:
SuperGLUE基于图像关键点匹配比CLIP特征匹配更可靠,成功率平均高出13%。这解释了为什么GOAT比COW的性能更好,因为GOAT使用了CLIP特征匹配。
引入匹配阈值来忽略低置信度会带来一定的代价,平均比没有阈值时差6%。这意味着在探索过程中匹配更具挑战性,而在环境完全探索后则更容易。
基于目标类别对实例进行子采样比遍历所有实例更有效,平均成功率高出23%。这解释了为什么GOAT比COW的性能更好,因为COW没有按类别进行子采样。
匹配实例视图的填充(扩大)边界框效果最好,平均比使用完整图像好4.6%,比使用对象的边界框好22%。
在所有设置中,匹配所有实例的所有视图的最大匹配分数比中位数、平均值和前2个平均值更好,平均提高2%到16%。
类似的趋势也可以在语言到图像匹配中观察到。然而,图像到图像匹配(使用SuperGLUE基于关键点匹配)比(基于CLIP的)语言到图像匹配更可靠,平均提高23%。




原文地址:https://blog.csdn.net/weixin_44887311/article/details/134670538
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_7085.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!