场景:
线上一个功能打开日志显示如下,ClientAbortException客户端中止异常,此功能在公司测试环境正常,另外线上的服务都是docker部署的,使用的是动态数据源,微服务库用的mysql库,业务库用的postgreSql库。
排查工具:
现象分析:
发现日志接口响应时间约69s了,而网关gateway中设置的响应时间为60s,超时所以客户端断开了,按理讲此时只要修改gateway客户端响应时间就可了,但是一个简单的接口怎么如此耗时呢?
第一:
用arthas的trace命令显示如下,在对象实例化的时候非常耗时。

配置排查。
cpu排查

负载排查:

内存,网络、磁盘IO排查
数据库:
索引,慢查询sql排查
表死锁排查

数据库的连接数排查
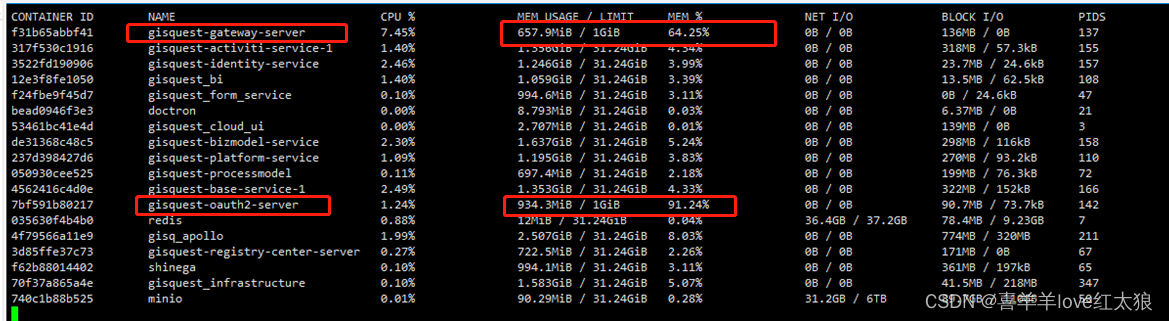
docker stats命令
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[Lucene]核心类和概念介绍](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)



