本文介绍: 通过将Laf集成到 Sealos云操作系统中,可以更高效地利用云操作系统的资源。用户可以直接在Laf中调用 Sealos 提供的各种数据库和服务,如 MySQL、PostgreSQL、MongoDB 和 Redis 等,以及消息队列和微服务,实现资源的最大化利用。这种集成方式使得Laf成为了一个功能更加全面的 Serverless 平台。尤其是在后端能力方面,这种集成提供了一个无缝的解决方案,弥补了传统 Serverless 平台的不足。
Laf 已成功上架 Sealos 模板市场,可通过 Laf 应用模板来一键部署!
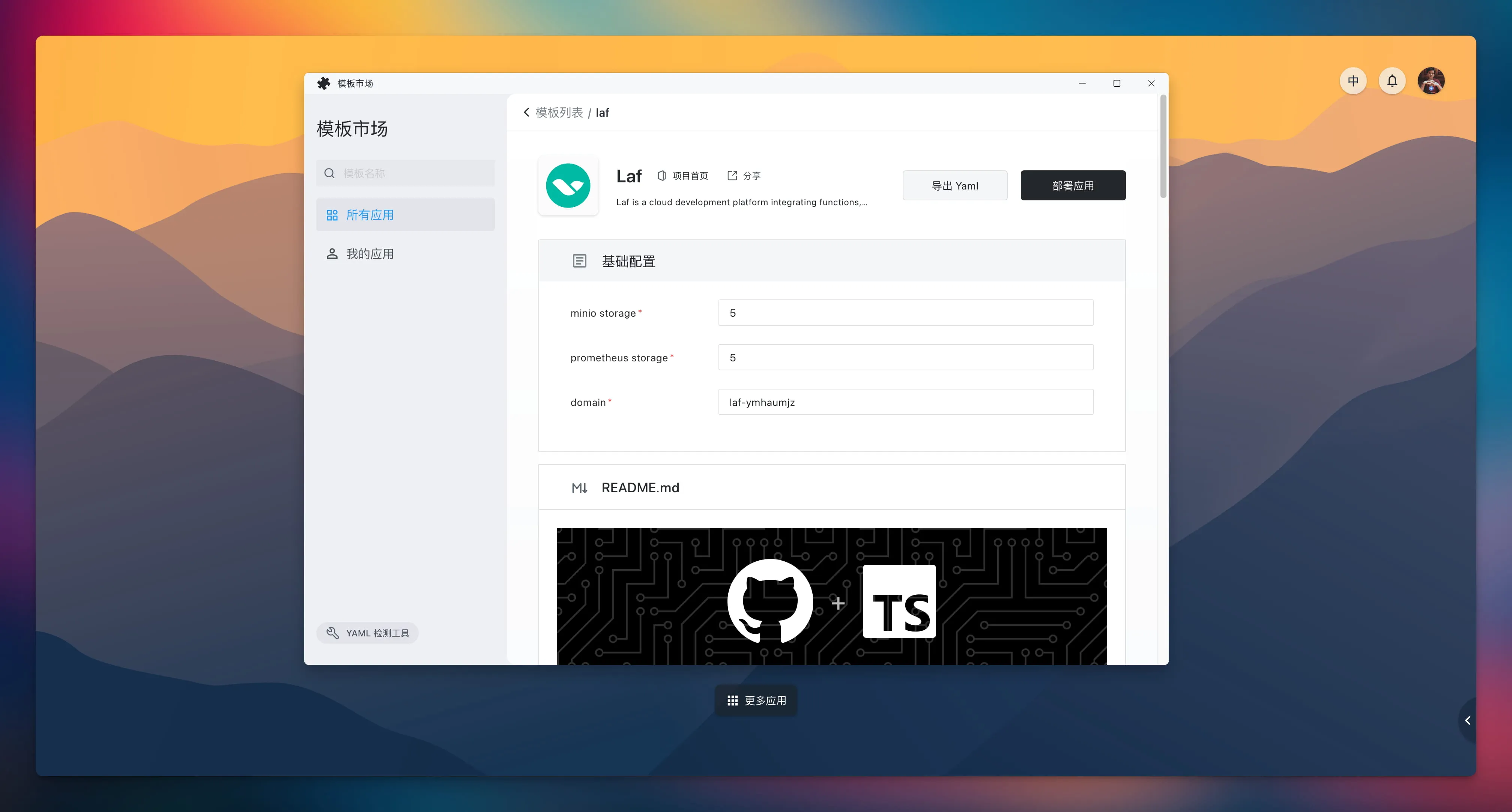
Sealos 作为一个功能强大的云操作系统,能够秒级创建多种高可用数据库,如 MySQL、PostgreSQL、MongoDB 和 Redis 等,也可以一键运行各种消息队列和微服务,甚至 GPU 集群上线后还可以跑各种 AI 大模型。
将 Laf 一键部署到 Sealos 中,我们就可以在 Laf 中直接通过内网调用 Sealos 提供的所有这些能力。无论用户需要什么样的后端支持,只需在 Sealos 上运行相应的服务即可。这种集成模式不仅提高了资源的利用效率,而且还提供了无缝的技术集成,使得 Laf 成为一个更加强大和多功能的 Serverless 平台,弥补了传统 Serverless 平台在后端能力方面的不足。
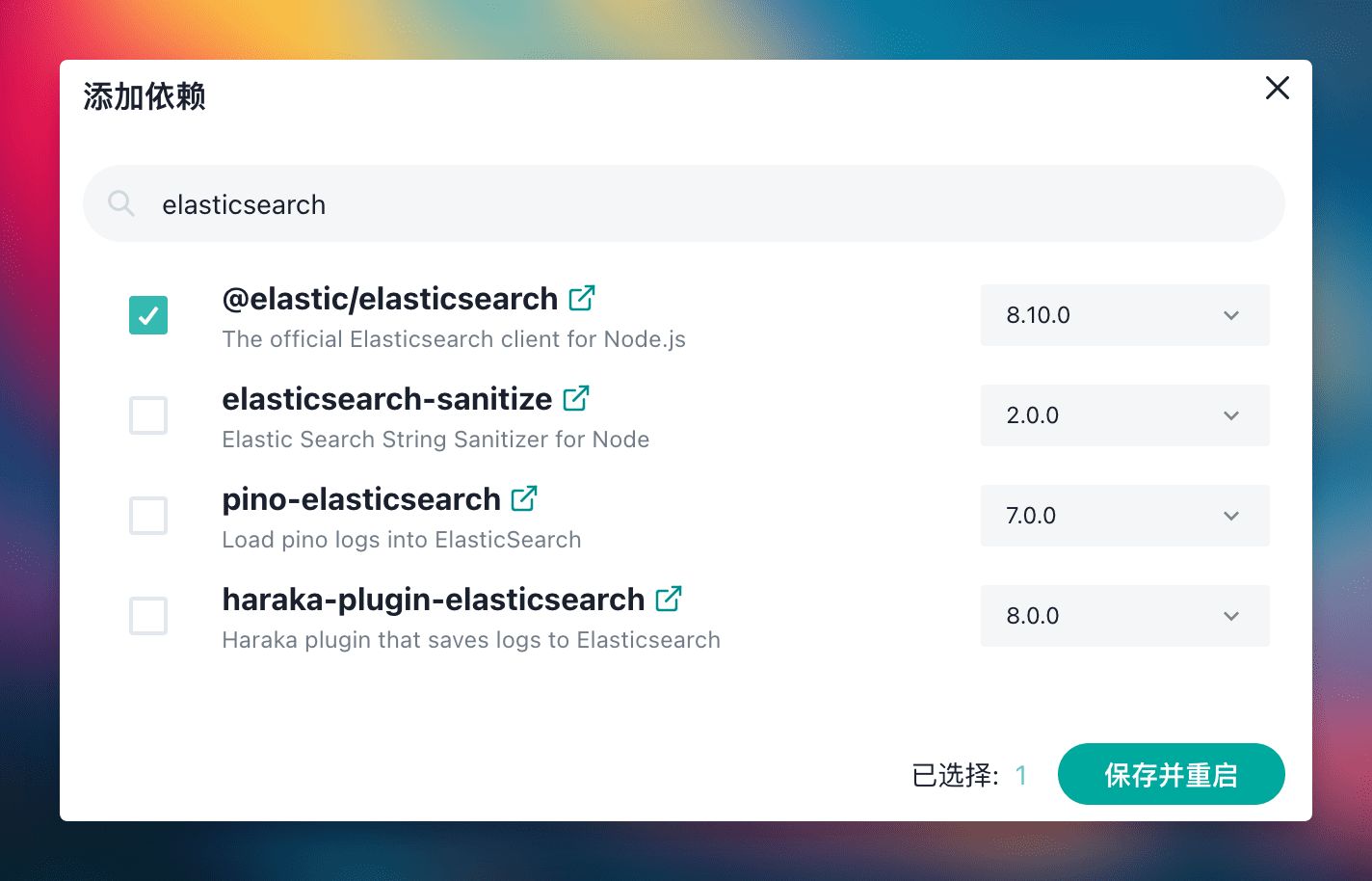
Sealos 强大的模板市场提供了丰富的应用生态,用户可以在模板市场中一键部署各种应用。本文以 Elasticsearch 为例,展示如何在 Laf 中调用 Sealos 模板市场中部署的 Elasticsearch 来搭建一个向量数据库,提供定制化知识库搜索能力。
背景知识
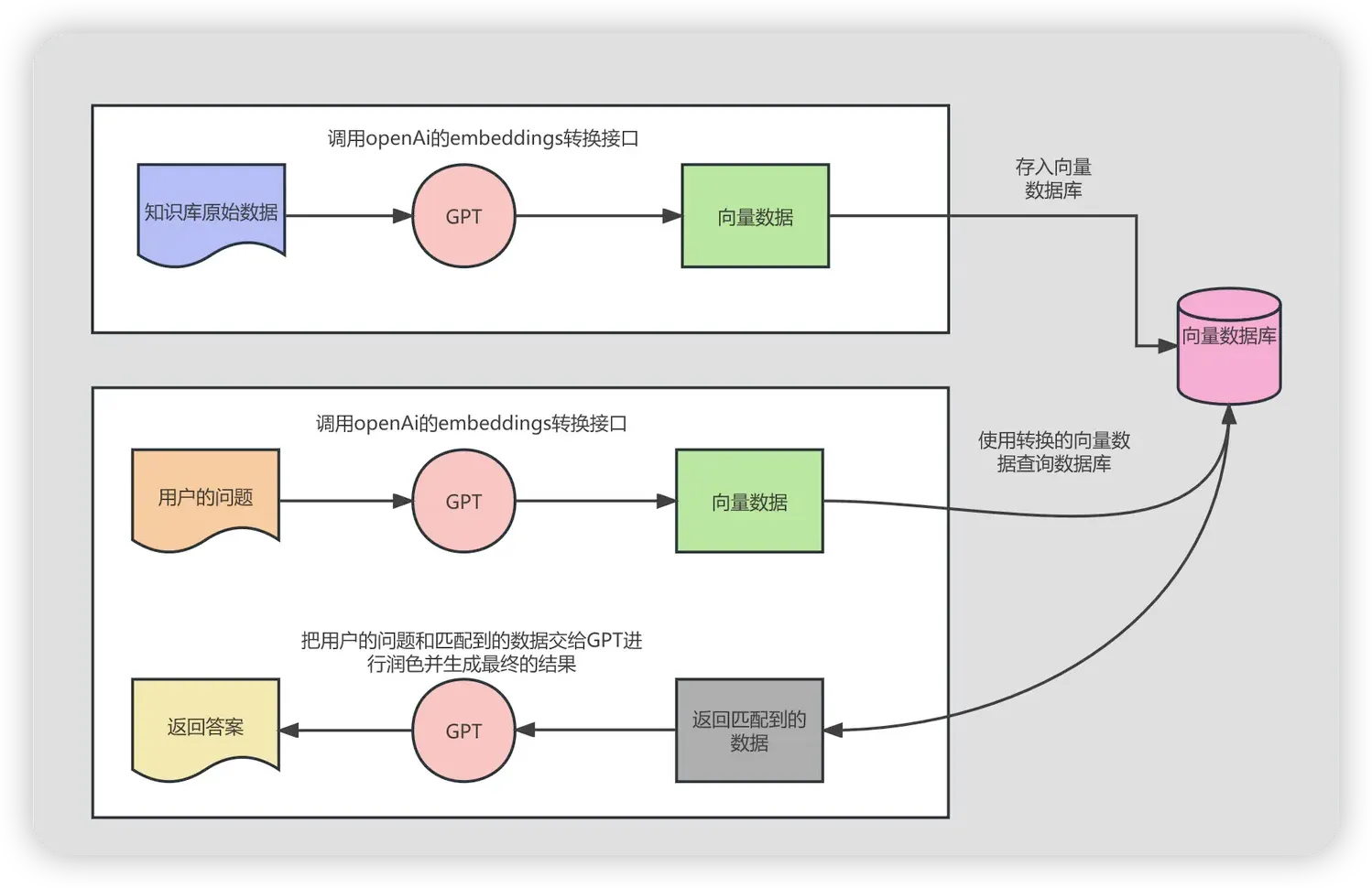
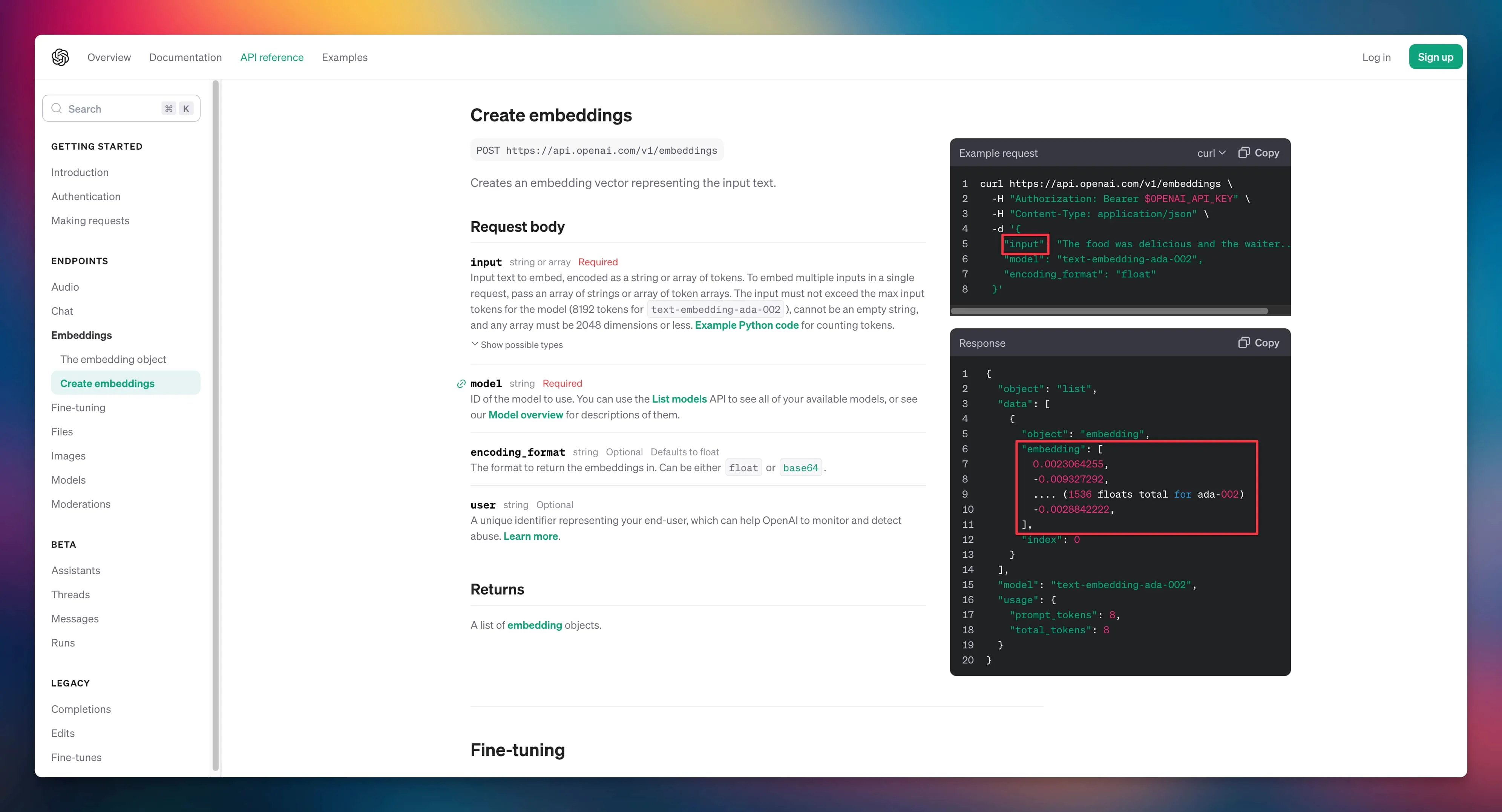
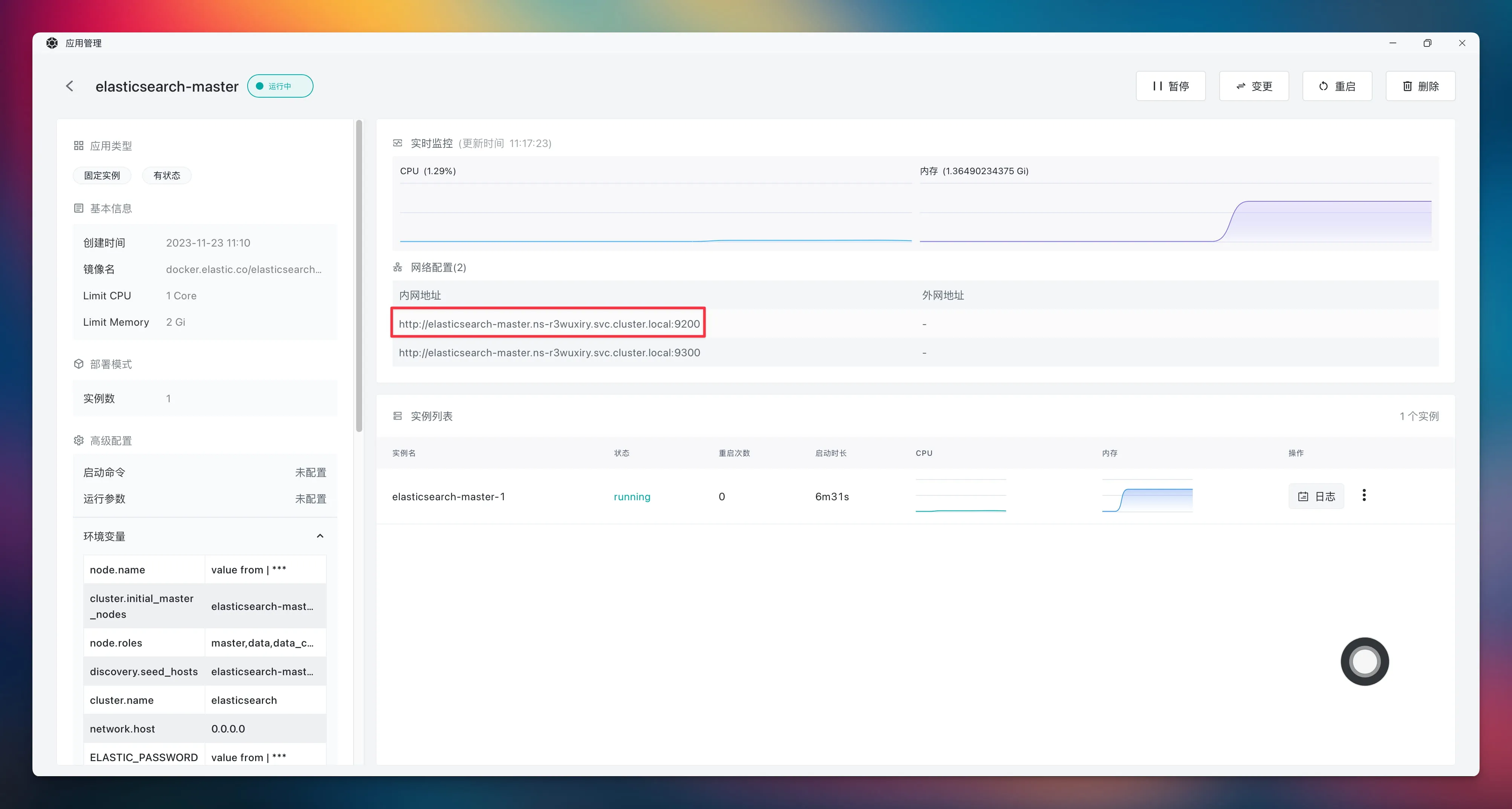
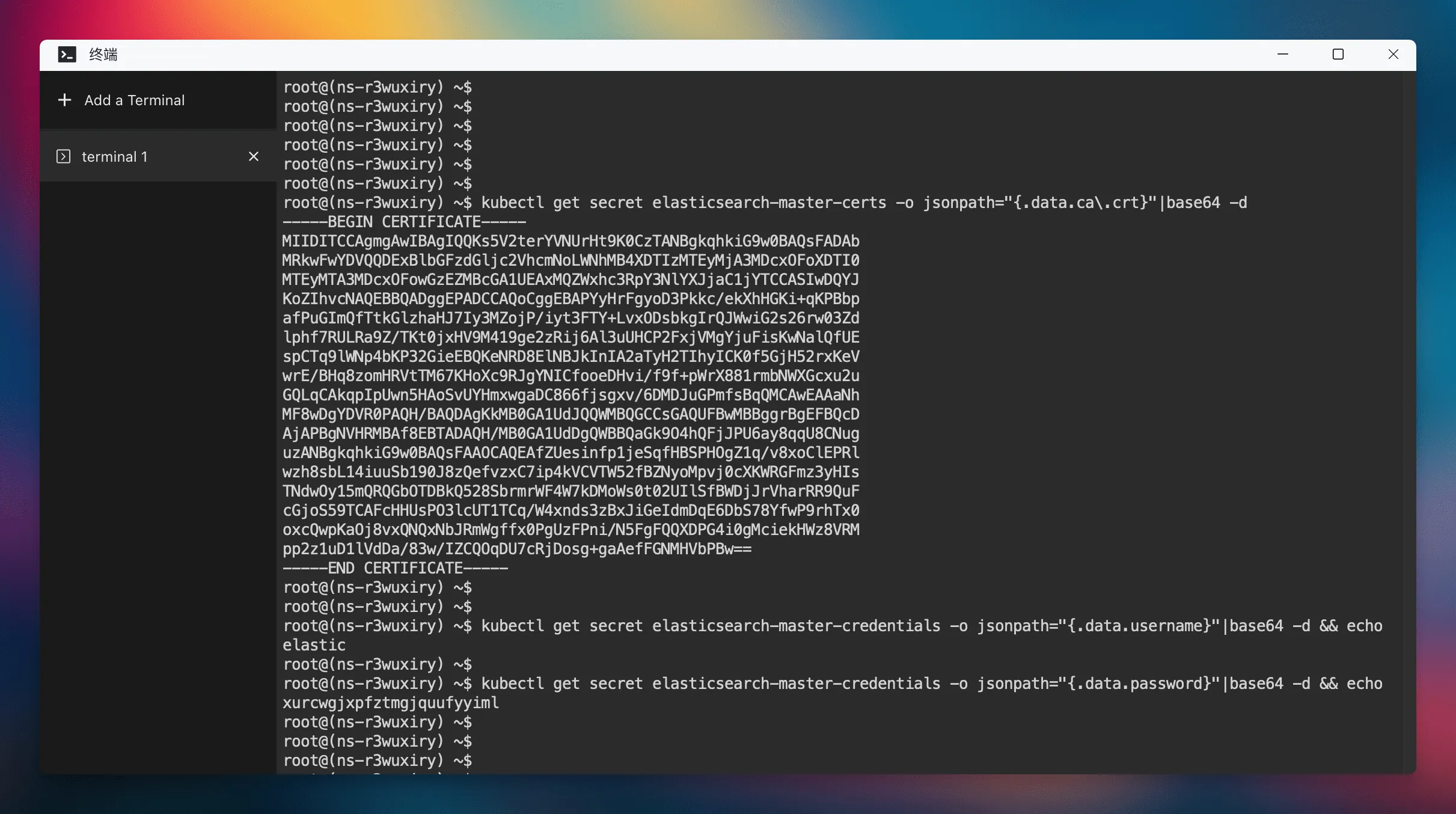
部署 Laf 与 Elasticsearch

总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。