本文介绍: 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
00 导读
2023年3月12日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。
01 什么是 Apache Paimon
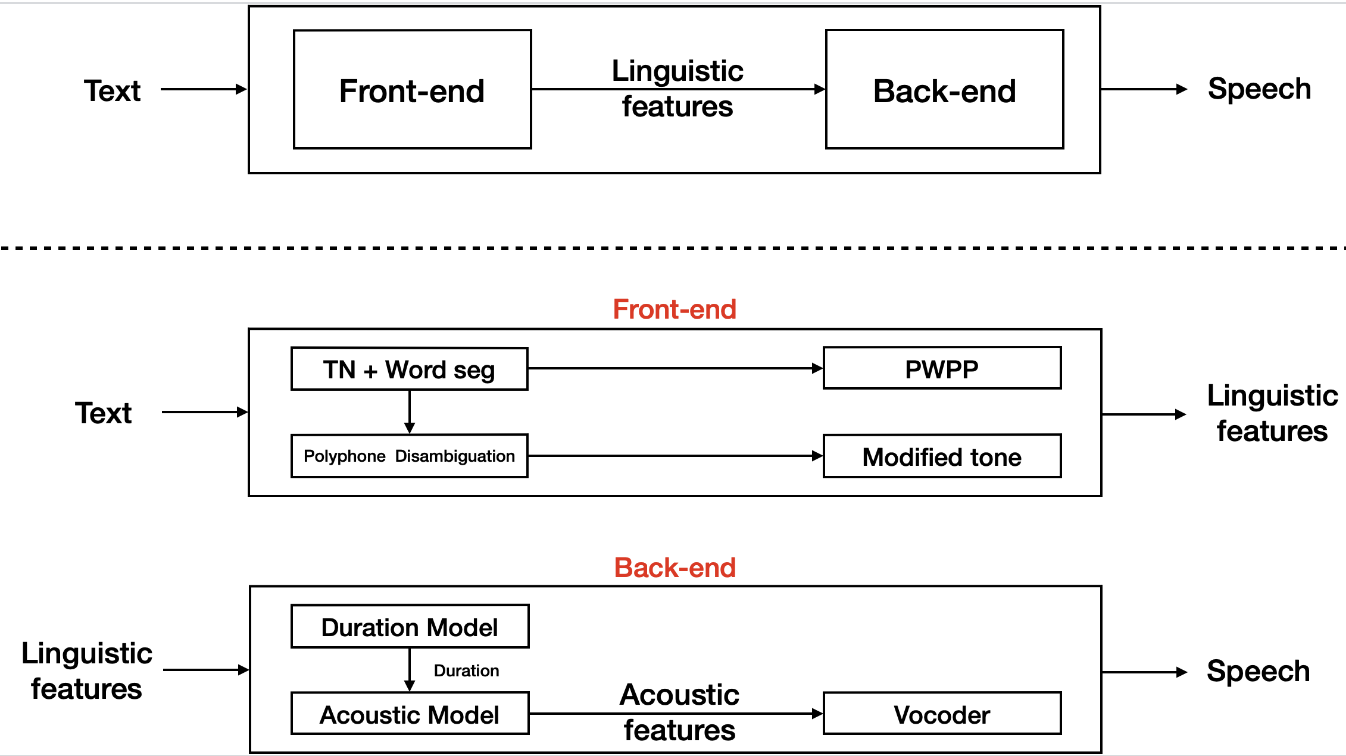
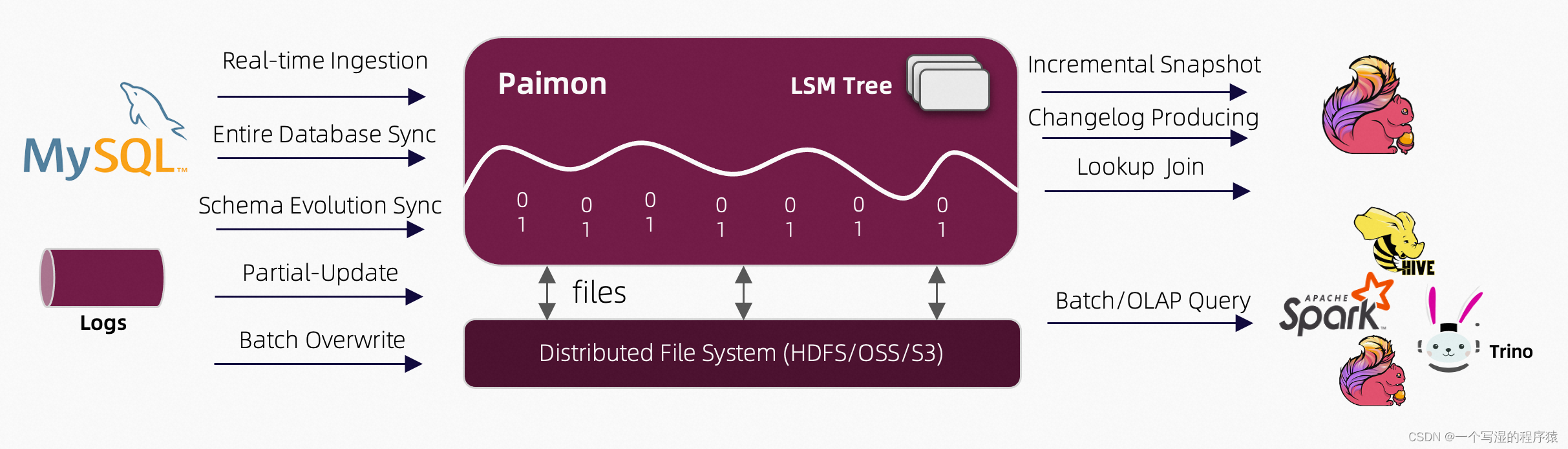
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。
Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。
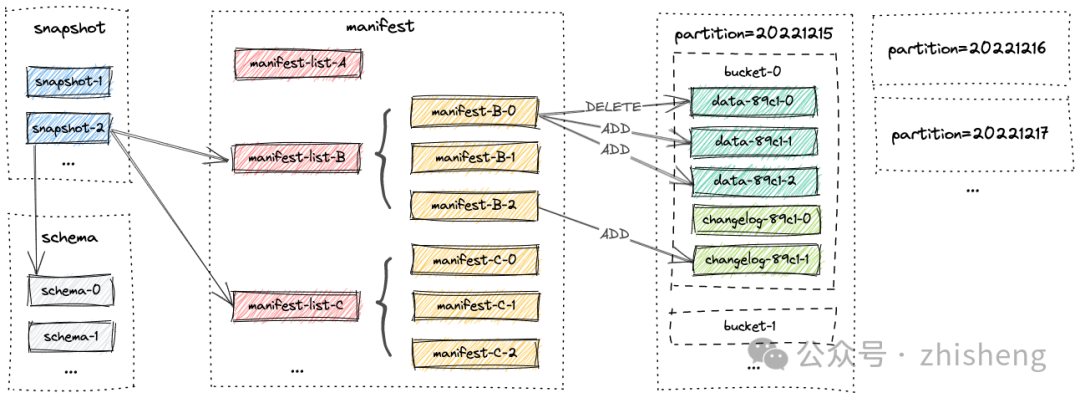
02 开放的数据格式
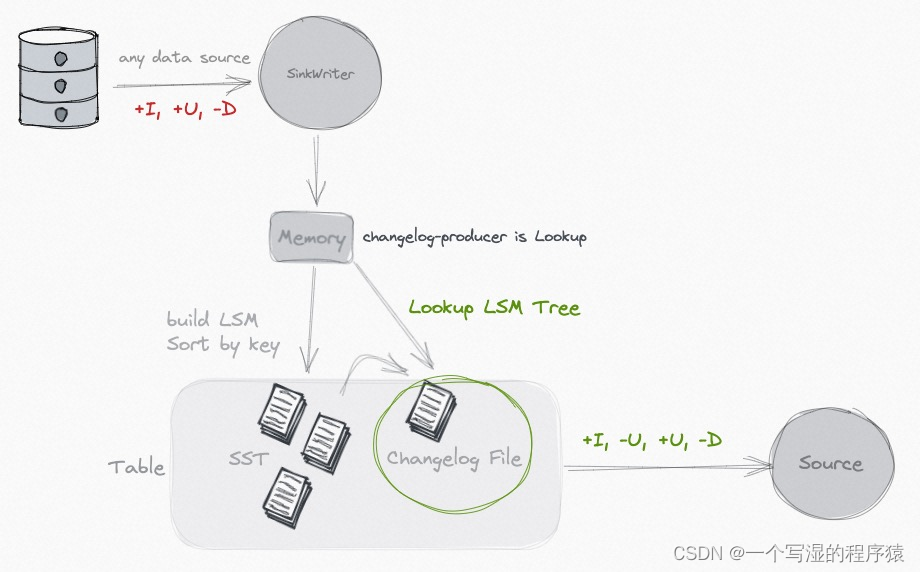
03 大规模实时更新
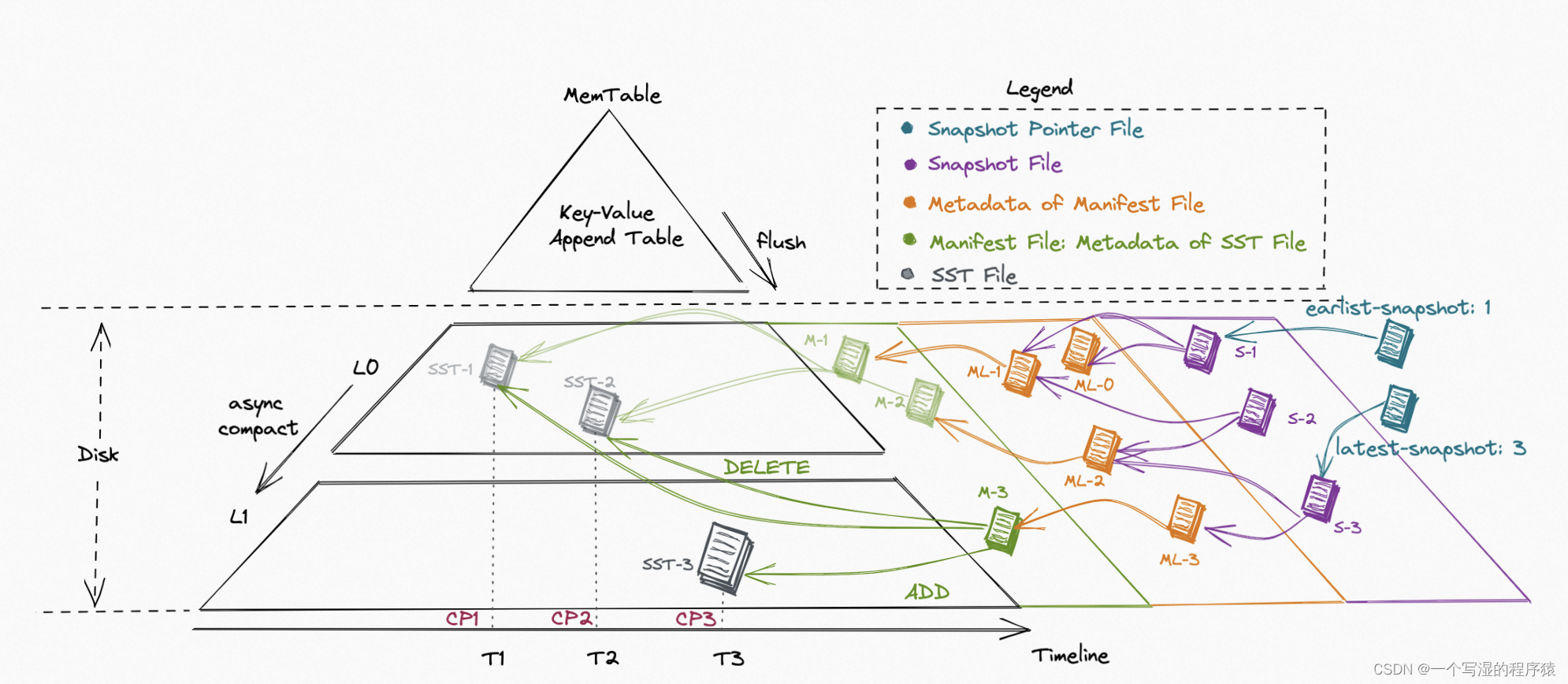
04 数据表局部更新

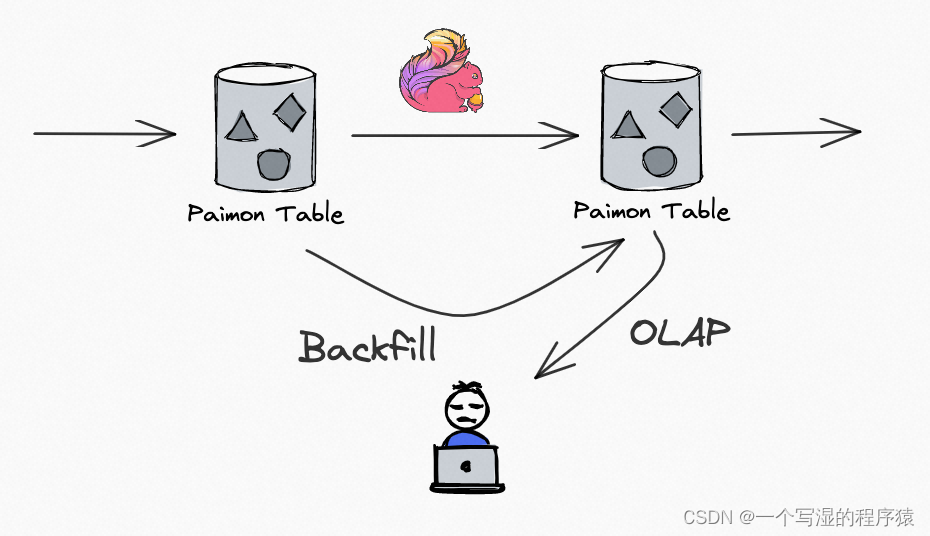
05 流批一体数据读写
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。