本文介绍: P(B|A)随着P(B)和P(A|B)的增长而增长,随着P(A)的增长而减少,即如果A独立于B时被观察到的。很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。贝叶斯定理的意义在于,在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则。解决上面的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况。:表示在没有训练数据前假设A拥有的初始概率,P(A)被称为A的先验概率。立的概率,称为B的后验概率。
1. 引入问题
有两个可选的假设:病人有癌症、病人无癌症,可用数据来自化验结果:正+和负-
有先验知识:在所有人口中,患病率是0.008,对确实有病的患者的化验准确率为98%,对确实无
病的患者的化验准确率为97%
总结如下:
P(cancer)=0.008, P(┐cancer)=0.992
P(+|cancer)=0.98, P(-|cancer)=0.02
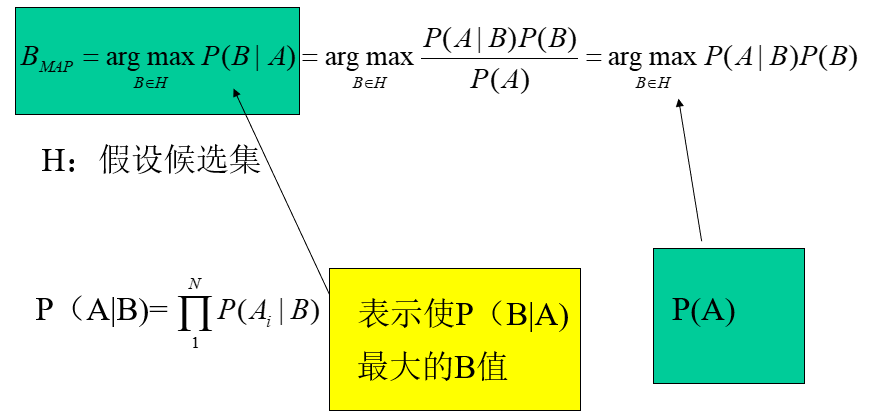
2. 朴素贝叶斯分类器
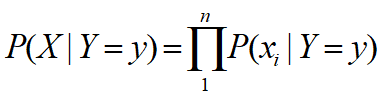
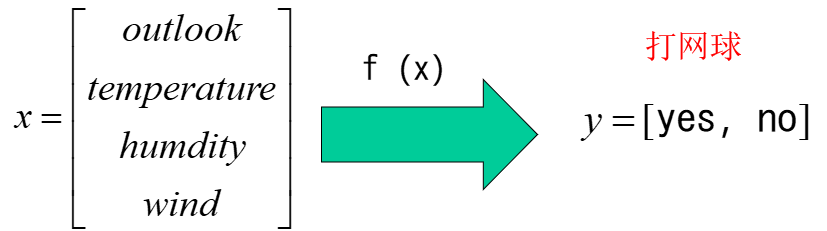


3. 多项式模型
4. 伯努利模型
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






