本文介绍: 文件名:要读取数据文件的名称(数据文件的绝对路径,可浏览选择加载),这个必须要填写,否则会报错Jmeter的绝对路径:1.当Jmeter脚本保存后,使用文件中的选择文件按钮打开时,默认显示的是jmx文件路径的窗口;换句话说:文件选择时,其相对路径的地址,就是jmx的地址——建议这种方式2.CSV文件的相对地址还有一个:Jmeter安装路径中的bin文件夹下文件设置的时候,为了兼容linux和MAC,层级的分隔符使用的是反斜杠,一般使用的是绝对路径,但为了其他人也可以使用脚本,这需要使用相对路径。
Jmeter学习三——CSV文件和关联
jmeter做功能测试和做性能测试的区别
- 性能测试,尽可能不要进行人为的干预,导致请求频率减缓(定时器,条件控制器,断言等)
- 性能测试脚本,追求自身的性能,能简单就简单
- 不必要的元件,能不用就不用
- 性能比较差的元件,也不要使用
- 性能测试脚本,是多线程同时执行,脚本中存在参数,就需要考虑多线程使用的情况
- 不能直接拿接口测试的脚本用于性能测试;功能接口测试的脚本还需要经过性能的转化,才能用于性能测试
CSV数据文件设置(读取外部文件,进行分数据驱动)
文件设置
- CSV数据文件设置,主要用来读取外部的数据文件,实现数据驱动测试
- 添加方法:线程组——添加——配置元件——CSV数据文件设置,如下图
- CSV数据文件设置,是配置元件,是最先执行的,如果CSV文件设置报错,后面的脚本都不会运行
- 若CSV文件在某个线程组下,其他线程组是无法访问的
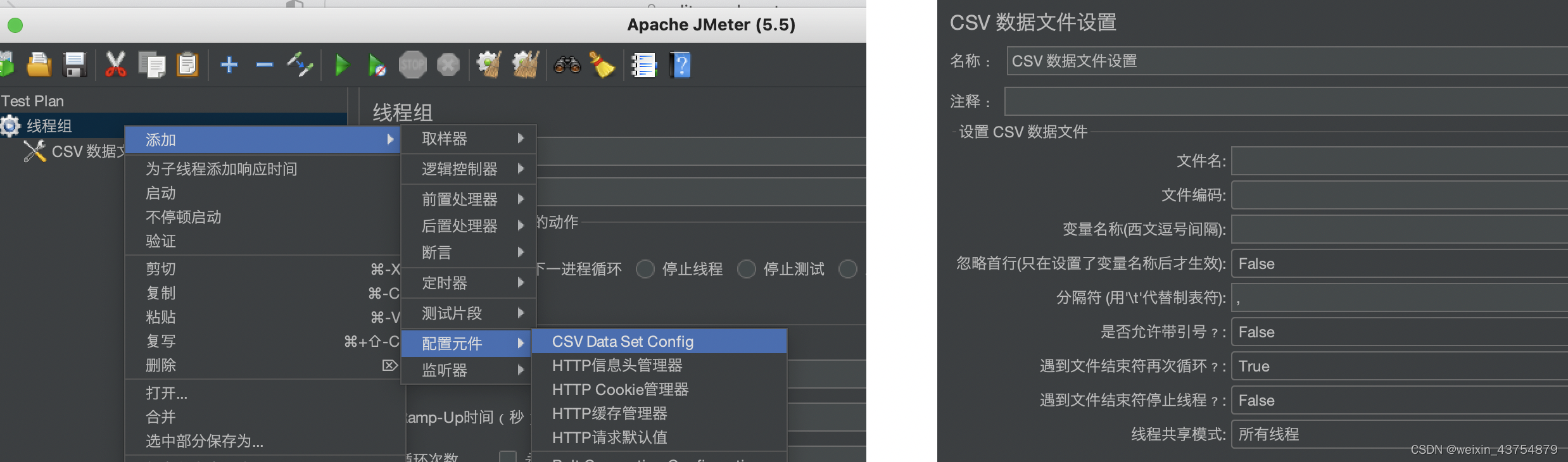
字段介绍:
文件名
- 文件名:要读取数据文件的名称(数据文件的绝对路径,可浏览选择加载),这个必须要填写,否则会报错
- Jmeter的绝对路径:
- 文件设置的时候,为了兼容linux和MAC,层级的分隔符使用的是反斜杠
/,一般使用的是绝对路径,但为了其他人也可以使用脚本,这需要使用相对路径 - CSV支持多种格式的文件,只要是文本文件,都支持
文件编码
- 文件编码:读取数据文件时,采用的编码,该编码设置要和文件名保持一致(utf-8、GBK等等,必须和CSV文件一模一样)
- txt文件,一般是utf-8
- CSV文件,字符集并不一定是utf-8,如果自身不是utf-8,但是Jmeter中选择了utf-8,中文信息就有可能出现因为字符集不同导致的乱码
- 因此,文件名那儿上传的文件,建议使用txt
如果出现编码问题导致的乱码,如何解决?
变量名
- 变量名称:读取数据是,接收列数据的变量,按列来接收,多列用多个变量接收,每个变量之间用逗号隔开
- 可以理解为变量名称为excel表格中第一列的表头,下面每一列的数据为文件中对应的数据
- 名称自己定义,逗号时候固定的,与文件中的列分隔符是什么没有关系
- 变量名中的第一个参数接受第一列,第二个参数接受第二列,依次类推
- 如果有两个变量名,想要接收三列数据,其中第二个参数想要接收第三列的数据没那么就需要在两个变量名之间使用两个逗号,例如:
username, , pwd
忽略首行
- 填写的内容只有True和False两个
- 为True:表示
- 为False:表示
- 这个功能表示读取文件的时候,要么从第一行开始,要么从第二行开始,不可能从中间开始
- 因此在做性能测试的时候,同一台机器上的多用户读取同一个文件,不会出现重复的情况,但是当服务器为分布式的时候,多台机器上都有相同内容的文件,每台服务器上的用户读取相同内容的文件的时候,就会出现使用同一个数据请求接口的情况
- 因此结论为Jmeter自带的CSV文件设置功能,在多台机器做助攻机,发起做性能测试的时候,会出现问题
- 解决方式:
分隔符
是否允许带引号
遇到文件结束符再次循环
遇到文件结束符停止线程
- 遇到文件结束符停止线程:文件所有数据加载完成之后,是否停止当前运行的线程
- True:表示遇到文件结束符就停止线程,意思是Jmeter会停止运行
- False:表示遇到文件结束符不停止线程,意思是Jmeter还会继续跑
- -如果线程有100个,数据只有10行(代表第10行后一个文件结束符),可以调用100次接口
- 【注意】“遇到文件结束符再次循环”和“遇到文件结束符停止线程”必须不一样,一个为False,另外一个必须时True,否则有一个设置不起作用(因为冲突导致下面一个设置失效了)
文件共享模式
设置下面的CSV设置项之后,要修改关联

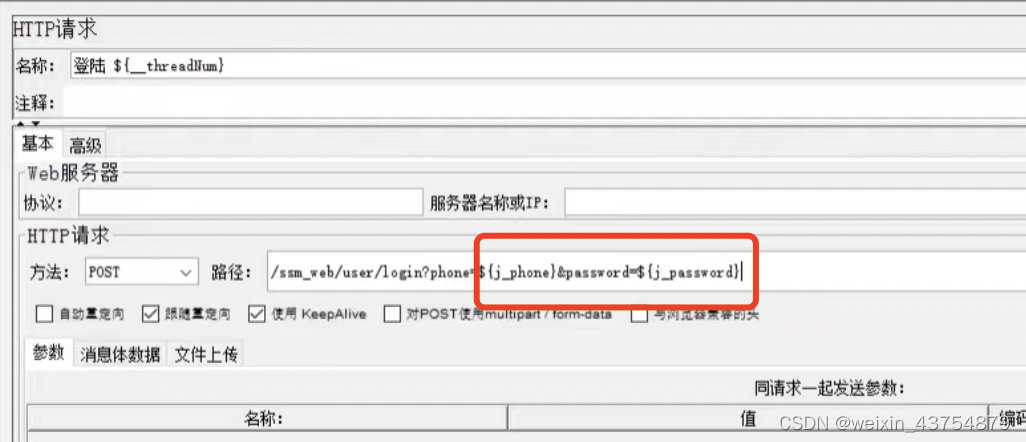
Jmeter关联
- 关联:将多个接口关联到一起,例如将上一个接口的响应数据,作为下一个接口的请求数据
- 实现方法:
- jmeter后置处理器有很多种,在此重点介绍3个
-
-
- 缺点:难以掌握,容易遗忘
-
-
-
- 缺点:只能提取json数据
-
-
- 边界提取器:确定左边界和有边界的信息,提取两个边界中间的数据
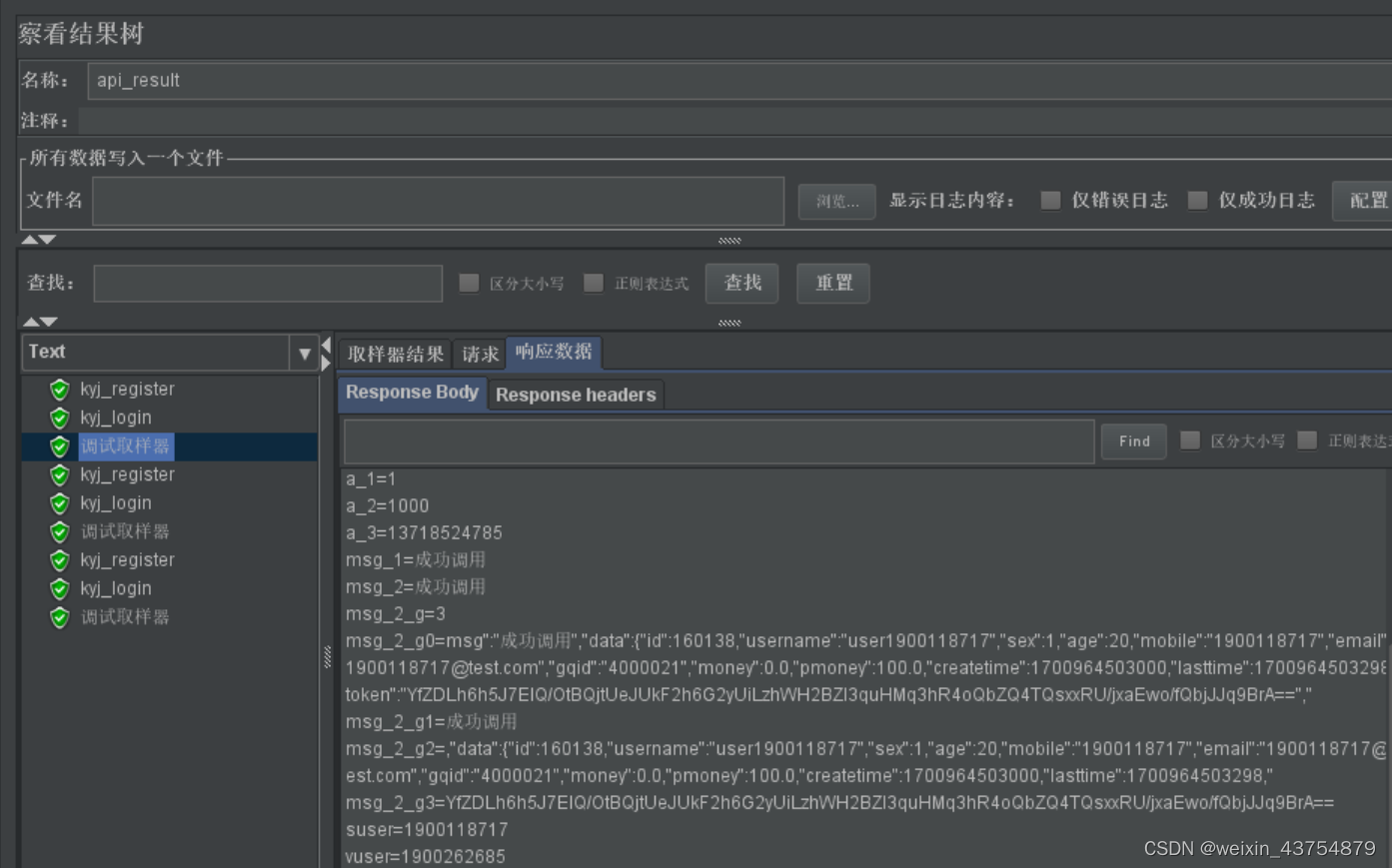
- 使用关联后,需要添加调试取样器来查看
-
- 添加方式:线程组——添加——取样器——调试取样器

正则表达式提取器
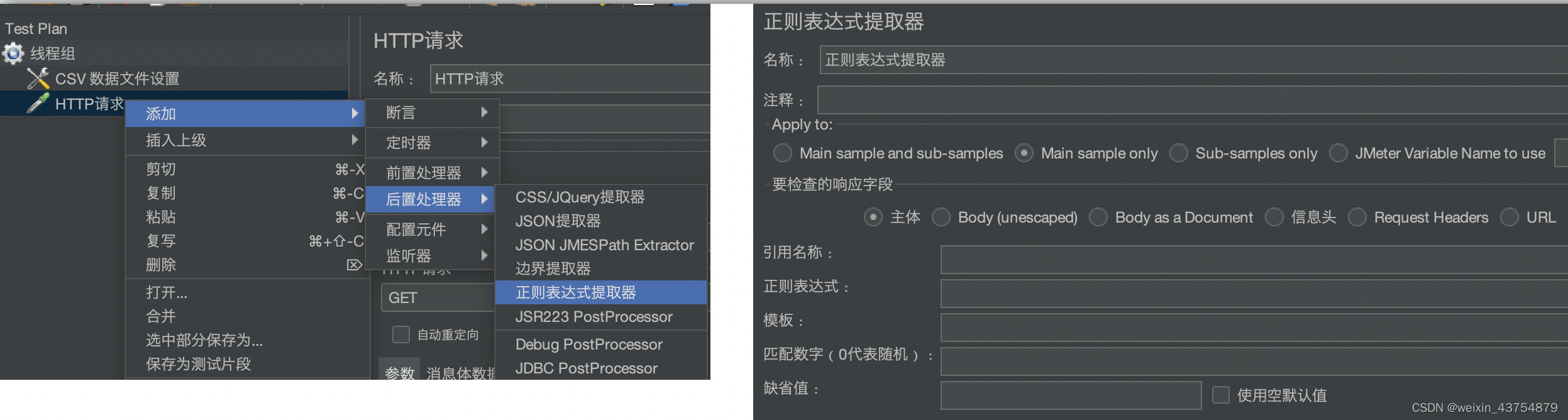
详情元素介绍
- Apply to:提取数据的接口
- 主请求和子请求的定义:
- 需要检查的响应字段:主要指要提取的数据,只能选择一个
-
- 主体:响应体
-
- 信息头:响应头
-
- URL:请求的URL
- 引用名称:匹配成功后,保存数据的变量名
正则表达式
- 填写正则表达式,正则表达式规则
- 需要掌握:
d w D W [^a-z] [^0-9] [0-9] [a-z] . + * ? ^;注意^在中括号内外的不同含义 - 万能正则表达式:
(.*?),几乎可以匹配任何文本 - 正则表达式文本框中,可以写多个正则表达式,但是需要
(.*?)作为分隔符隔开 - 例如下图的表达式和结果
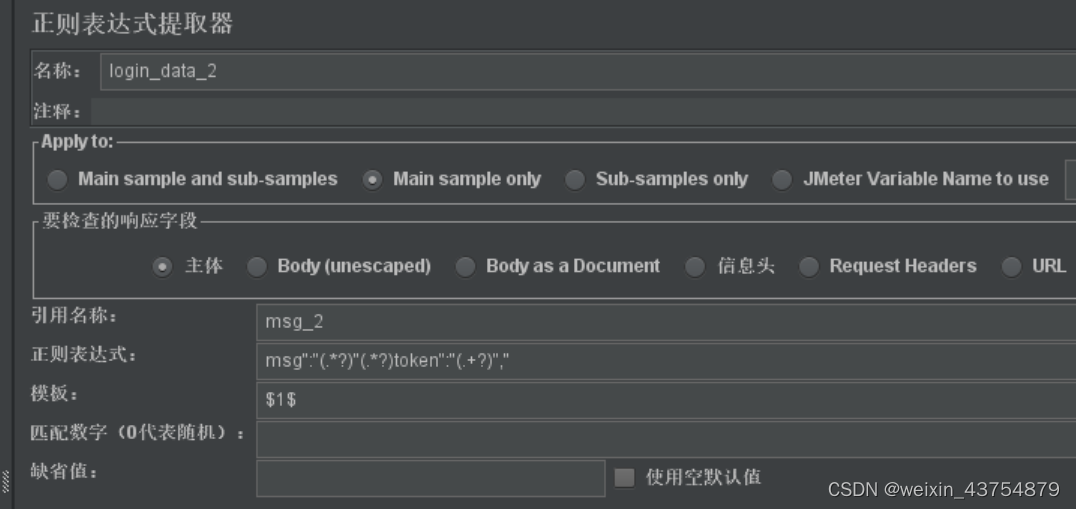
注意事项:
模板及匹配多组数据的使用
- 匹配出多组数据时,可以通过模板选择具体某种组合,或者全部数据
-
$1$:选择第一组数据
-
$2$:选择第二组数据
- 匹配数字(0代表随机,-1代表全部):按照正则表达式提取数据,按照模板筛选之后,如果数据还有多余,可以使用匹配数字选择某一组数据保存到引用名称的变量中
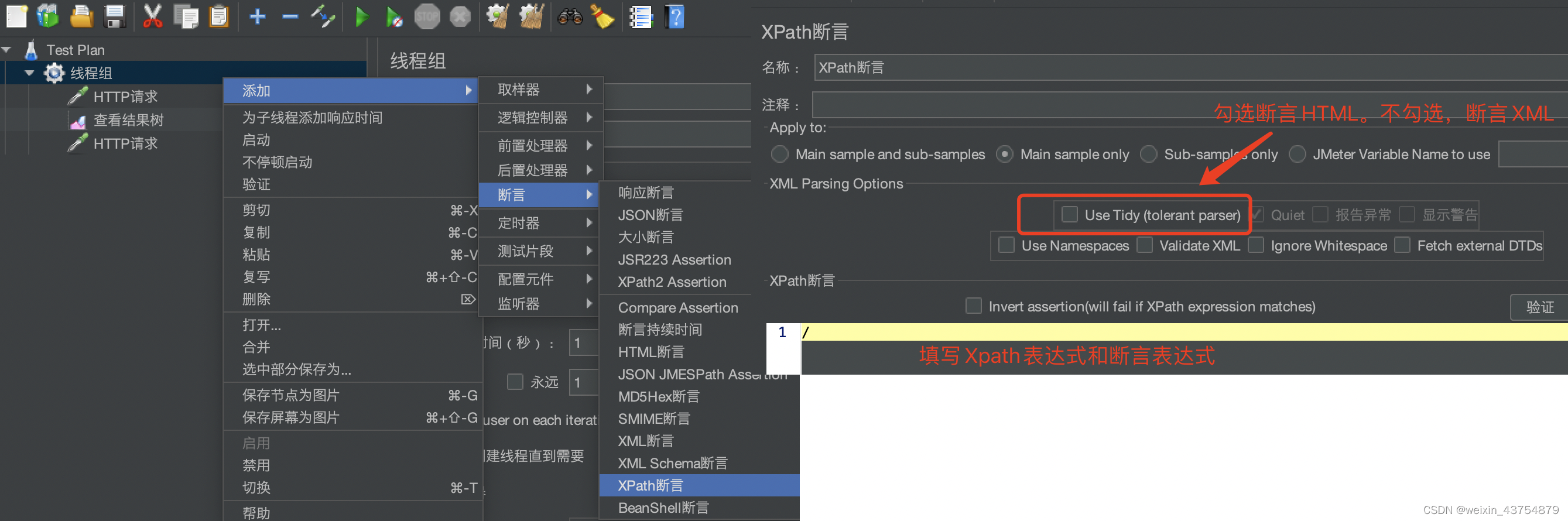
Xpath提取器
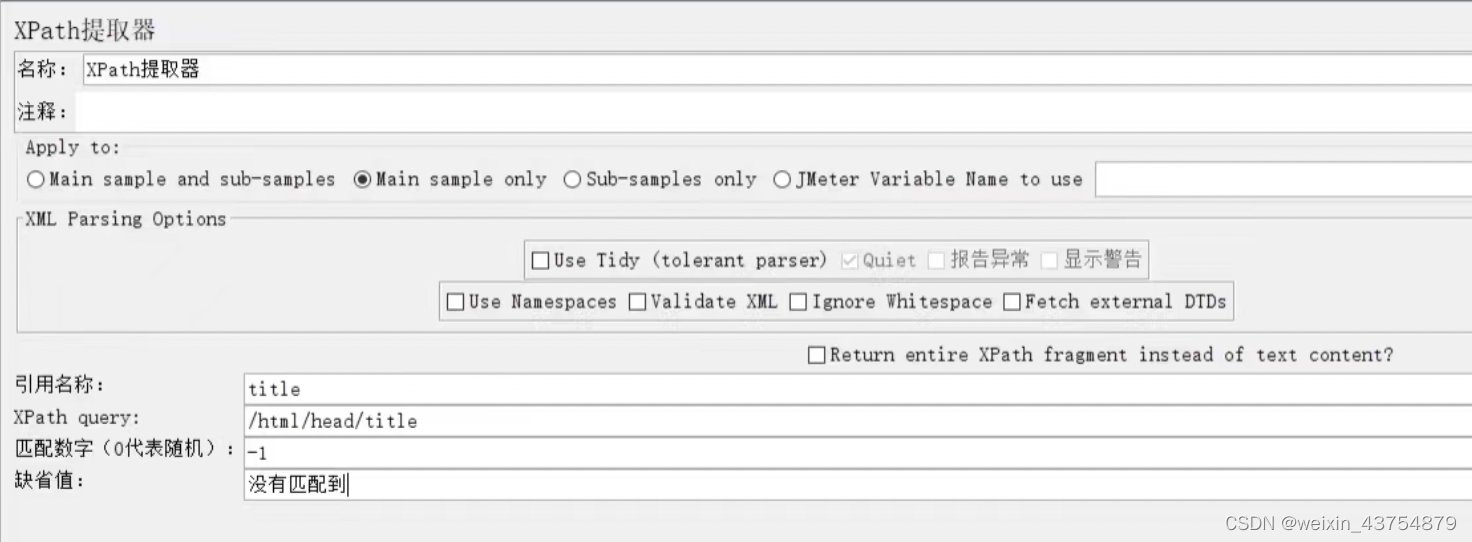
详情元素介绍
- XML Parsing Options:XML的解析器
- 引用名称:使用Xpath表发誓提取出来的数据,保存到引用名称设置的变量中
- Xpath query:填写Xpath表达式的地方
- 匹配数字:
-
- 1,代表全部
-
- 1,选中匹配的数据列表中的第一个数字
-
- N,选中第n个数字
- 缺省值:没有匹配到时的默认值
Xpath表达式
json提取器
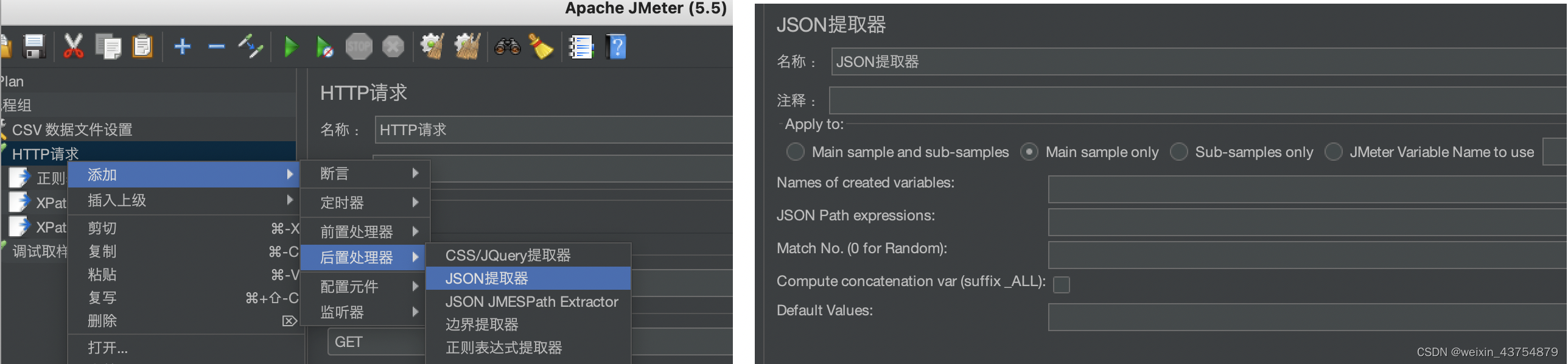
详情元素介绍
- Names of creat variable:保存的变量,后面接口要使用的变量名
- JSON Path expreesion:JsonPath表达式,通过JSON表达式提取数据
- Math No.(0 for Random):如果JSON表达式中提取了多组数据,那么按照数字选择某组数据
-
- 0表示随机一个设置
- Compute concatenation var(suffix_ALL):如果JSON表达式提取器提取了多组数据,并且勾选了Compute concatenation var(suffix_ALL),那么自动拼接所有数据,以逗号作为分隔符,然后保存到Name of creat variable设置的变量中
- Default Values:默认值
- 一个json提取器,可以写多个jsonpath提取方式,多个jsonpath提取式可以使用英文的分号隔开,这个时候就必须填写 Default Values
JsonPath语法
-
- $表示提取根节点的数据
-
- $.a表示从根节点开始,寻找根的字节点a,并提取a的数据
-
- $.a.b表示从根节点开始,寻找根的字节点a,并返回b的数据
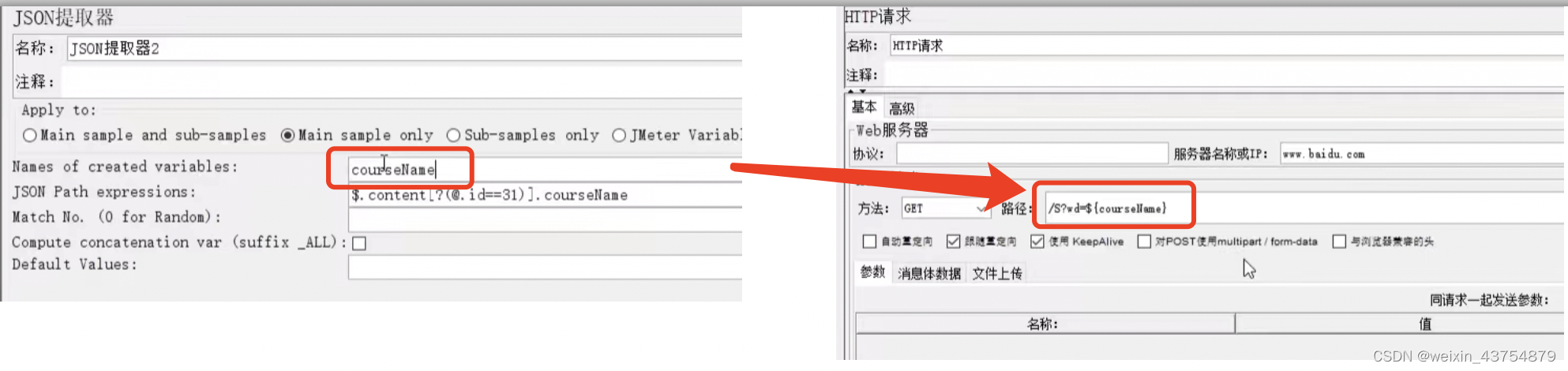
- -$.a[条件].b如果一个字节点a是列表,那么可以这样写,代表提取a列表中,满足【表达式】筛选条件所有数据中,节点b的值
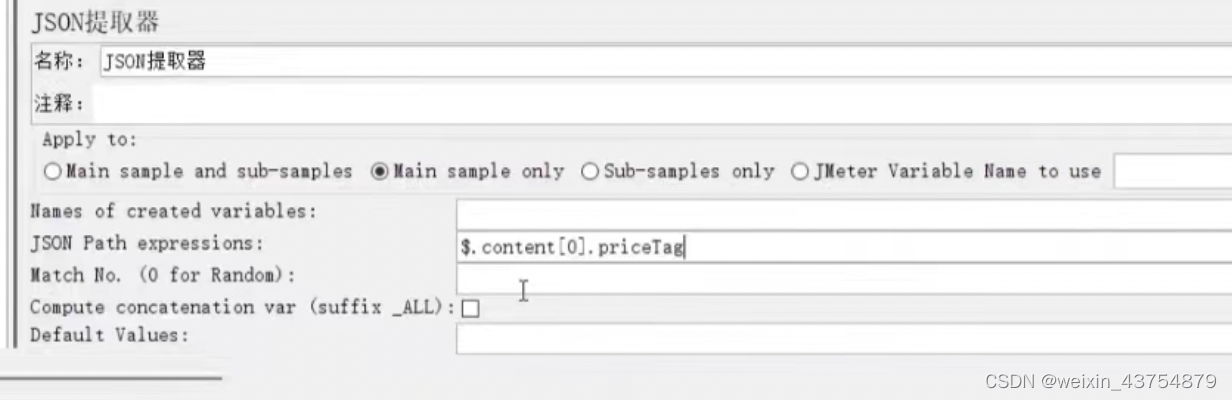
- 比较复杂的表达式:$.content[?(@.id)==31)].courseName,具体规则
- 拿到json信息后,按照规则,将参数名写在具体位置上
边界提取器
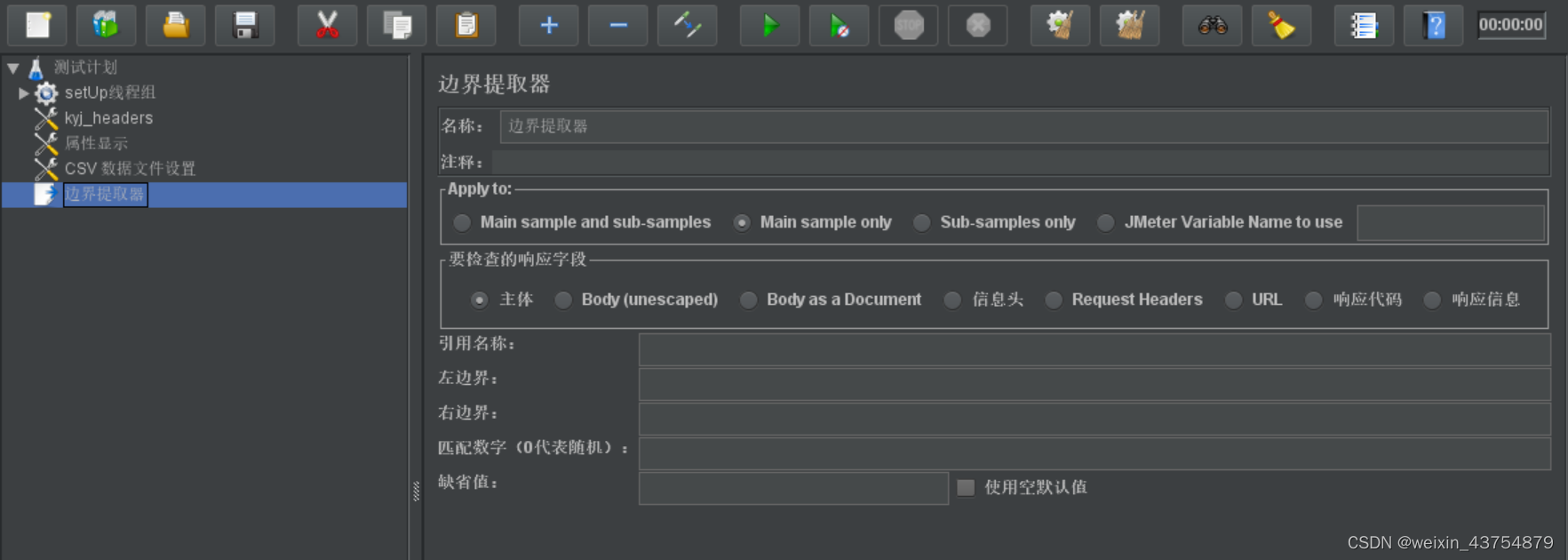
页面元素介绍
Jmeter断言——性能测试脚本中不建议写
性能测试中的断言
- 断言:预期结果和实际结果,进行比较,一致,说明没有问题,不一致说明有bug
- 因此在一定时间内,发起的请求数量减少了,也就造成了短时间内对服务器造成的总压力不足,对服务器进行的性能测试的结果指标误差就更大了
- 因此,从这个角度来讲,不建议在性能测试脚本中写断言
再次强调
- 在性能测试中,默认的成功与失败只和状态码有关,与响应结果内容的准确性无关
- 默认成功的状态码:1XX、2XX、3XX
- 默认失败的状态码:4XX、5XX
- 如果加了断言,就是人为强制的讲响应结果的正确性与jmeter的成功和失败挂钩,也就人为的干预了测试结果
- 因此也就人为的干预了性能测试的结果指标(成功率),那么性能测试的结果就出现了错误的判断
- 从这个角度来讲,也不建议性能测试脚本中写断言
疑问:脚本中有断言,但是性能测试时禁用可以吗?
断言的介绍
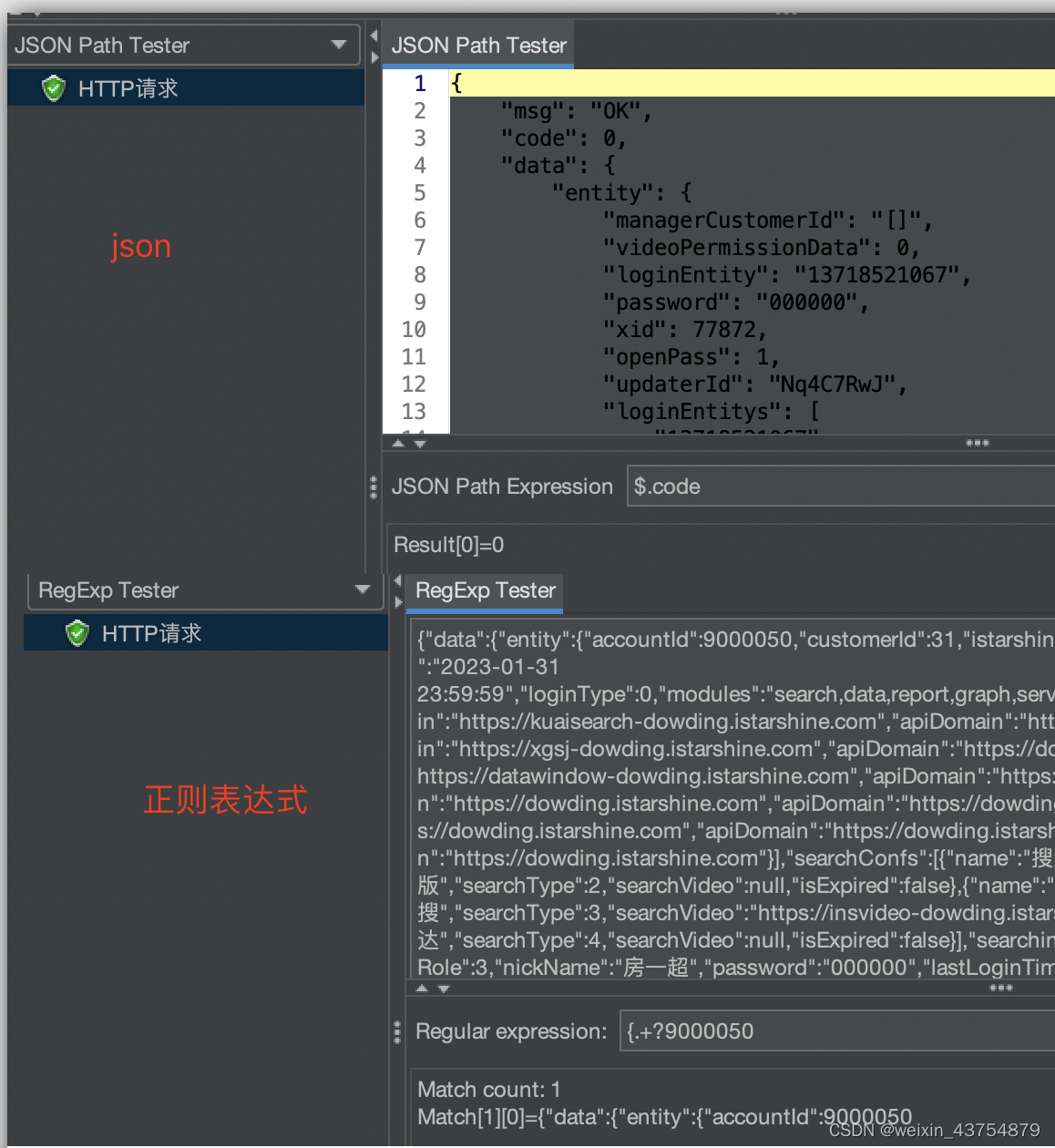
响应断言
- 添加方式:取样器——添加——断言——响应断言
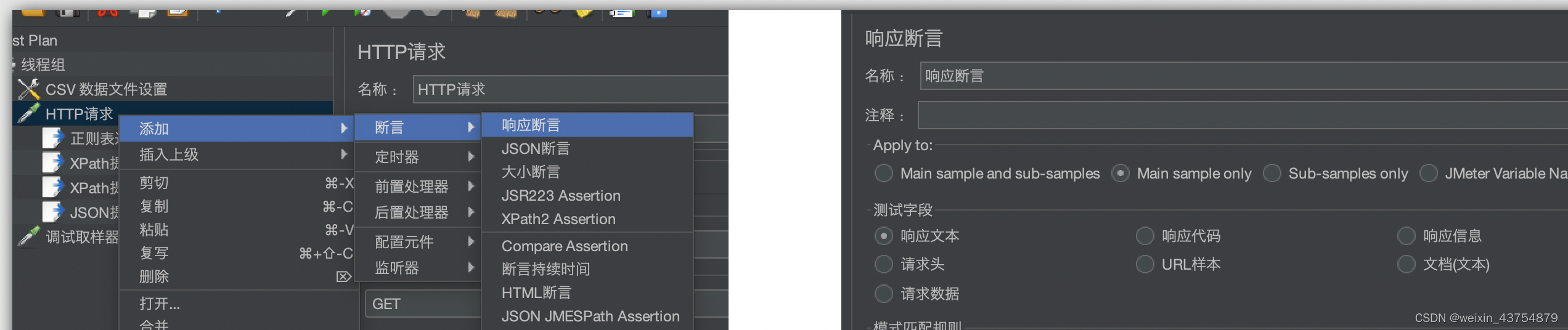
- Apply to 选择对主请求和子请求生效
- 测试字段:窗口包括请求数据和响应数据,在这里可以根据选择,断言部分请求数据和响应数据,以及全部数据
-
- 响应文本:断言响应体的内容(推荐)
-
- 响应代码:断言响应状态吗(200)
-
- 响应头:断言响应头
-
- 请求头:断言请求头
-
- URL样本:断言请求的URL
-
- 忽略状态:不断言响应状态吗
-
- 请求数据:断言所有请求数据
-
-
- 否:取反
-
-
-
- 或:如果响应数据满足【测试模式】中任何一个指定的规则,则断言通过
-
-
- 如果断言通过,查看结果树前面都是绿色的对号;如果断言失败,查看结果树中会显示红色的叉号,并且断言未通过的接口下会有一个字节点“响应断言”
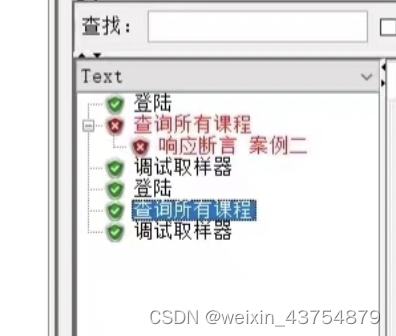
-
- 断言样例如下:
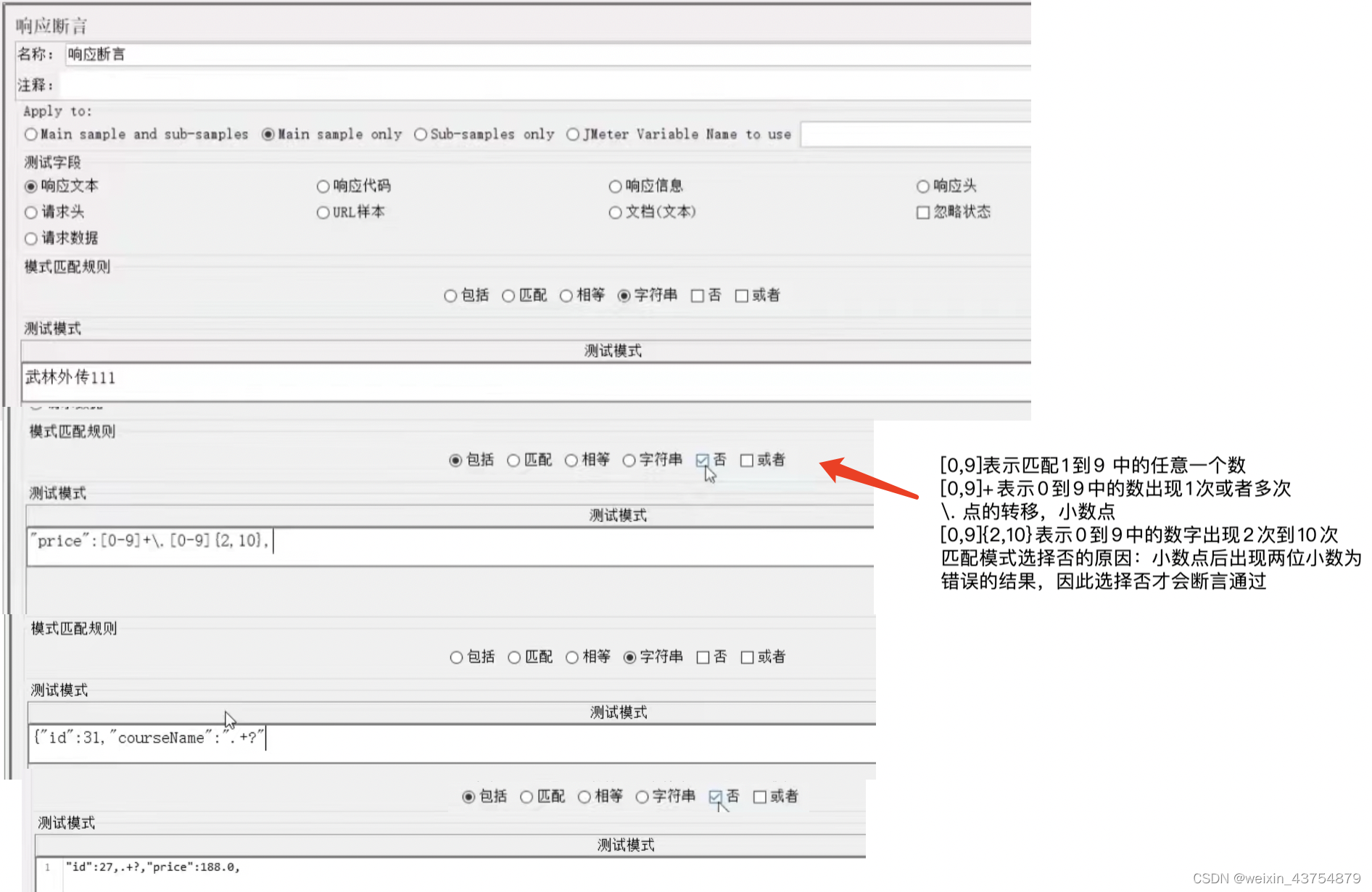
- 断言样例如下:
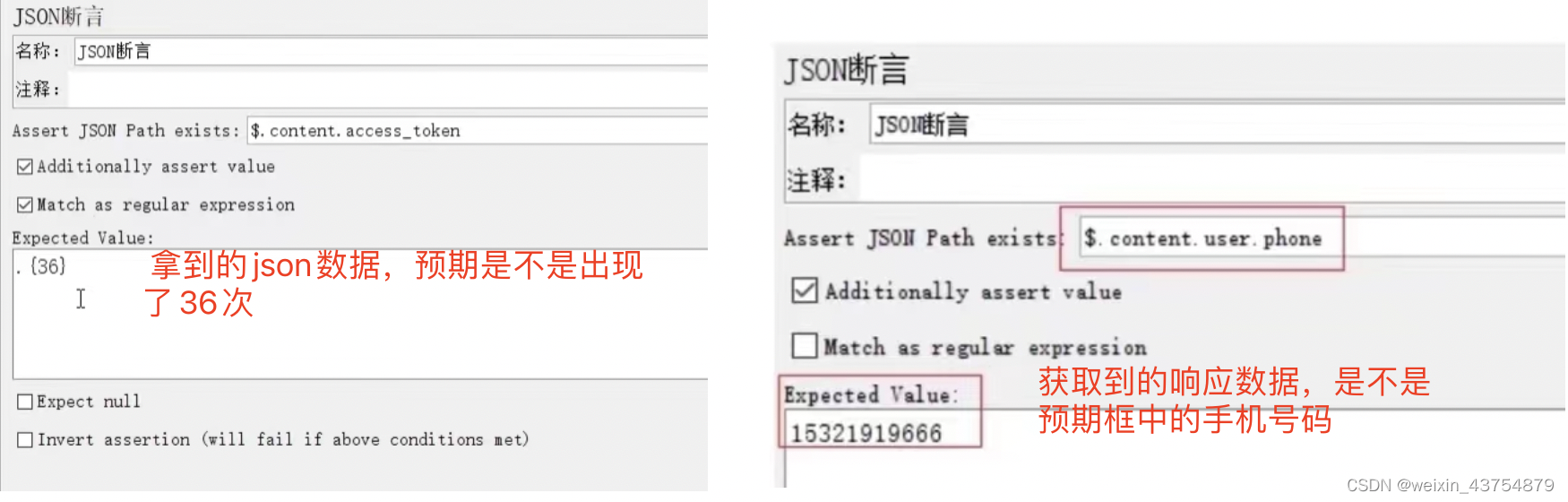
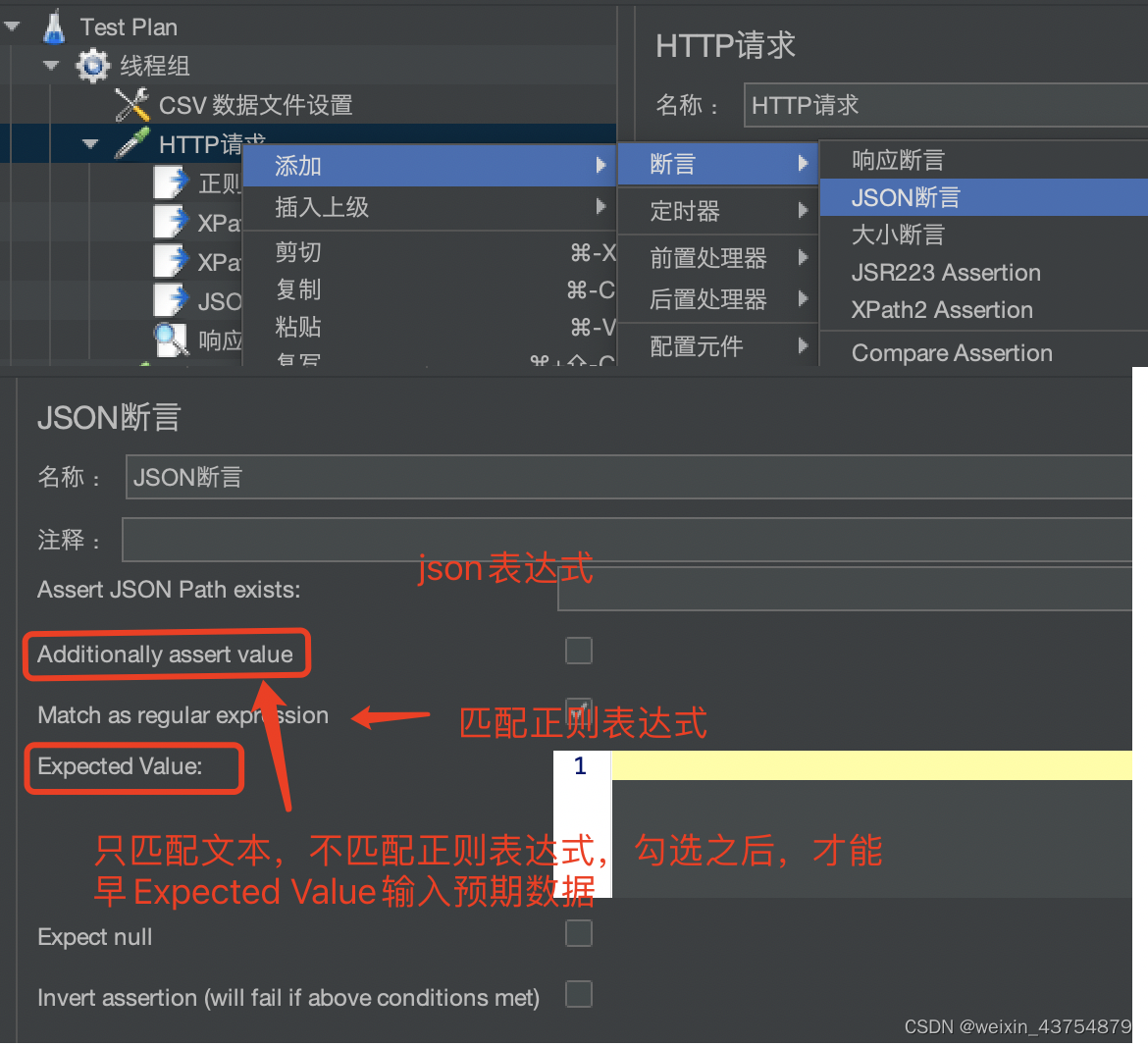
JSON断言
- 添加方法:取样器——添加——断言——json断言
- 作用:和响应断言相比,json断言只能对json结构的数据进行断言
- 当响应体是json结构的数据时,我们使用json断言比响应断言的性能更好
- 断言规则:
-
- 先判断断言的目标数据是不是json数据,如果不是,断言失败
- 样例如下:
Xpath断言

jmeter生成测试报告
- jmeter是不能直接生成HTML测试报告,需要借助工具Ant来生成
- Ant是采用java语言编写,主要作用是对程序进行编译、组装、测试和运行java程序
- 再jmeter这里,我们主要是使用ant运行jmeter文件,生成测试报告
- 安装Ant,下载网址
-
- 配置环境变量
export ANT_GOME= ANT的解码路径
export PATH= $PATH:$ANT_HOME/bin
- 验证ant安装成功的办法,在cmd或者终端总,输入ant -v,如果显示版本号就说明安装成功了
- 安装成功后,还要进行:
-
-
- ant要运行的jmeter的脚本名称
-
-
-
- ant生成html报告的内容
-
- 使用jmeter生成HTML报告,需要以下步骤
-
- 第一步:保存jmeter脚本(方式:文件——保存测试计划为),这个保存的就是最终要运行的脚本文件
-
- 第二步:保存jmeter脚本运行时,生成的文件数据(查看结果树中,直接在文件名中写入路径信息,就会将数据文件保存到相应的路径下)
- 保存测试计划和数据文件时,最好与bulid.xml、jmeter-results–detail-report_21xsl放在一个路径下
- 运行时,在cmd或者终端中,输入ant -f build.xml后,会生成html的测试报告
- build.xml中,决定测试计划和数据文件名称的地方如下图示例,名称必须和配置文件保存一致


Jmeter定时器——性能测试中不建议使用
性能测试中的定时器
- jmeter中,如果在线程组中添加了定时器,会对所有的取样器都有效,添加之后,所有的取样器(例如HTTP请求,调试取样器等)都会等待定时器设置的时间之后再使用下一个下取样器
- 定时器会延缓发送请求的频率,从而导致对服务器的请求阿里变小,这样就反应不了服务器额真是压力
- 例如:原本1min可以调用1000次接口,加了定时器之后可能只能调用100个,因此对服务器造成的压力就不足了
- 因此,性能测试过程中,不建议使用定时器
性能测试过程中的集合点(同步定时器)
- 集合点或者同步定时器,是讲所有接口集合在某个点之后,瞬间发起请求,会造成某一秒对服务器的瞬间压力,但是压力过去之后,又需要等待一定的时间再去对服务器发起瞬间请求,场景就是一瞬间的压力,等待,再一瞬间的压力,一定时间之内发起的请求数可能还会小于不加集合点发起的请求
- 这种和不添加集合点,持续对服务器进行很大的压力相比,不添加集合点会更容易发现性能测试的问题
- 因此,也不建议性能测试中添加集合点
定时器的介绍
思考时间
- 线上所有用户平均操作的间隔时间
- 思考时间的计算公式=线上活跃用户数/每秒点击数
- 思考时间的添加方式:线程组——定时器——统一随机定时器
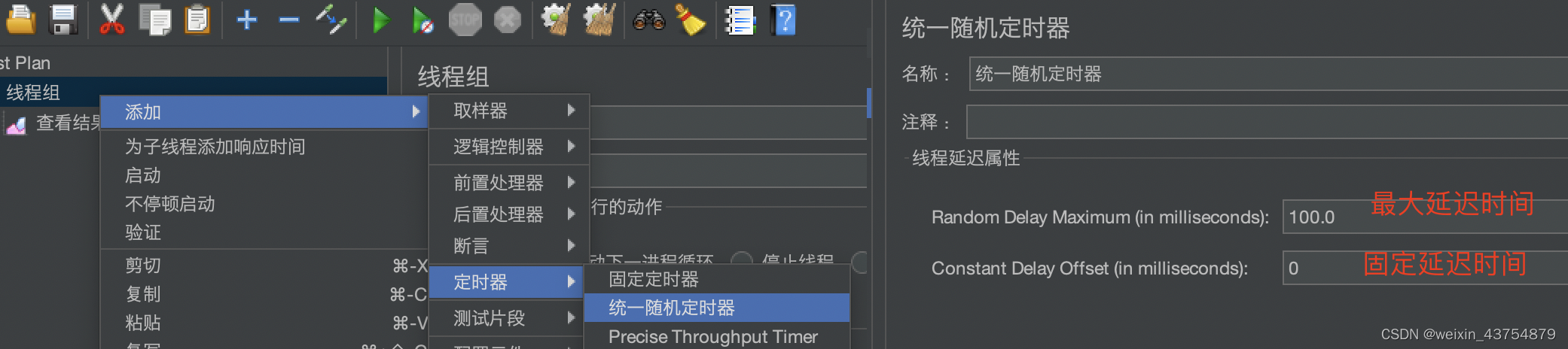
- 上图中的固定延迟时间可以理解为最小等待时间
- 统一随机定时器设置的思考时间 = 固定延迟时间+不超过最大延迟时间的随机值
- 如果固定延迟时间设置1000毫秒,最大延迟时间设置为9000毫秒
-
- 那么思考时间在一个1秒到100秒之间的随机数
-
- 如果想设置固定值,就不设置最大延迟时间就可以了
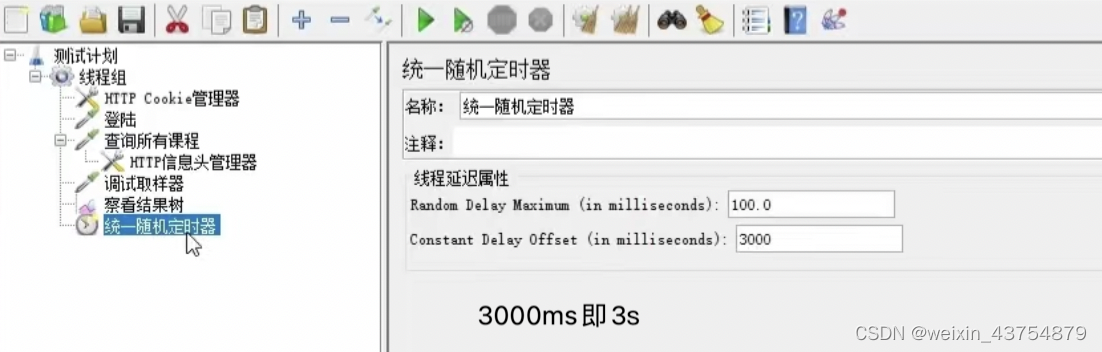
- 如果想设置固定值,就不设置最大延迟时间就可以了
同步定时器(集合点)
- 在接口测试中,同步定时器主要用来进行幂等测试
- 在接口的性能测试中,同步计时器主要作用是用来进行并发测试
- 幂等测试:判断请求完全一模一样的服务器是否能够正常处理
- 并发测试:同时发送多个请求,验证服务器的并发处理能力
- 幂等测试是并发测试的一种,但是幂等测试更关注“完全相同”,而并发测试关注发送多个接口请求
- 添加方法:线程组——定时器——同步定时器
-
- 模拟用户组的数量和测试计划中的线程组数量必须一致
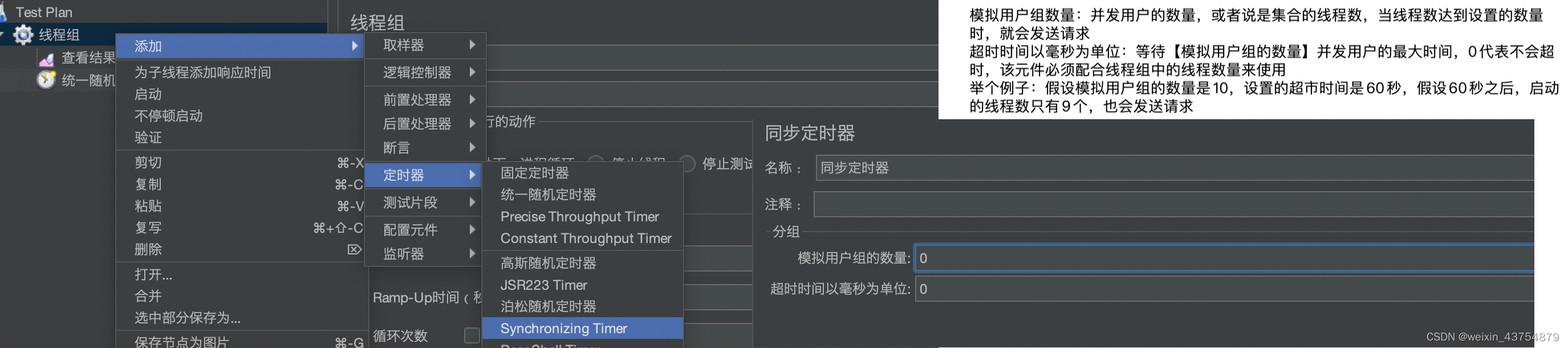

- 模拟用户组的数量和测试计划中的线程组数量必须一致
jmeter逻辑控制器
性能测试中的逻辑控制器
逻辑控制器的介绍
- 作用:控制父子节点和控制执行流程、
- jmeter的逻辑控制器,主要包括循环控制器,if控制器和For each控制器3中
- 这三种控制器,分别用来进行循环控制,条件控制和跌倒控制
-
- 循环控制器:相当于python中的for循环
-
- if控制器:相当于python中的if条件循环
循环控制器
- 添加方式:线程组——逻辑控制器——循环控制器
- 作用:使用同一个请求体,重复发起相同的请求
- 如上设置完成之后,HTTP请求必须是逻辑控制器的子节点时,才可以完成循环
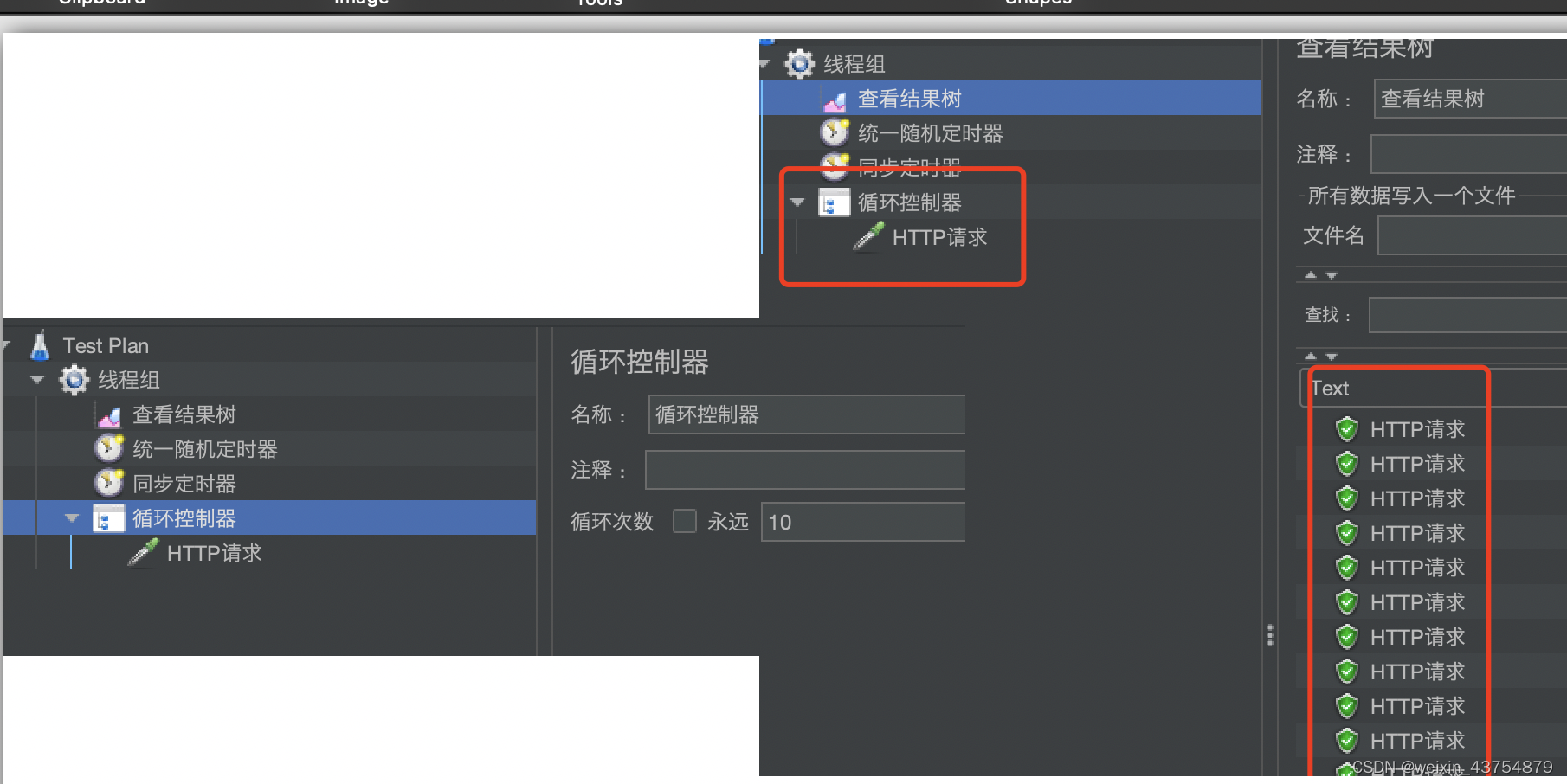

条件控制器——性能测试中几乎不用
- 条件控制器的添加方法:线程组——添加——逻辑控制器——if控制器
- 必须使用groovy或者jexi3的函数,文本框中的结果必须是True或者False
- 使用场景:就是Expression文本框中的条件表达式结果为真或者为假,结果为真的情况下,if控制器中中的子节点取样器会被执行;为假的情况下就不会去运行其子节点中的取样器
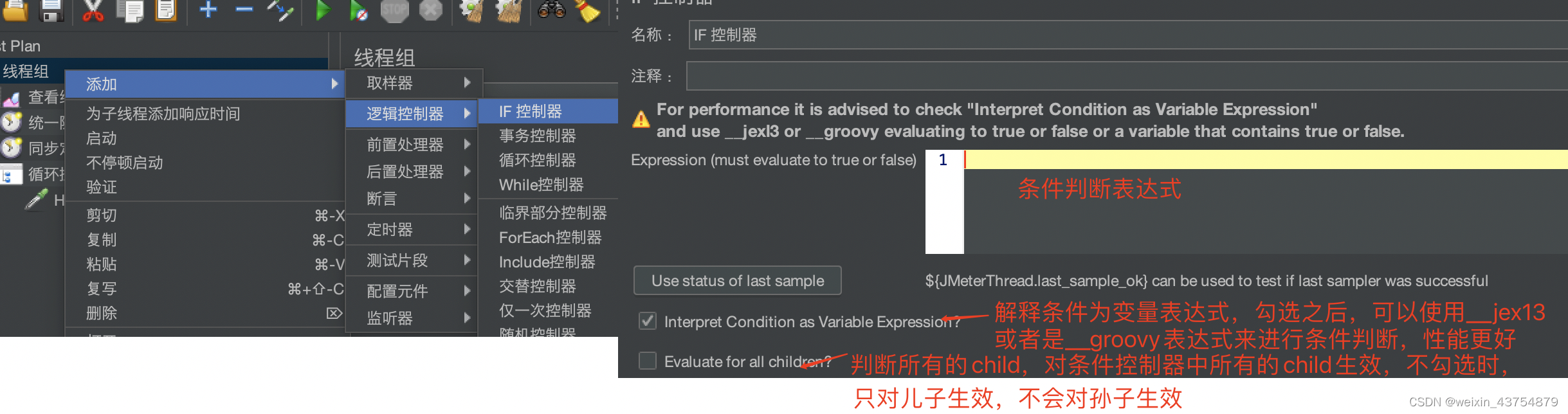
- 如何通过jmeter实现测试环境和开发环境的切换?
- 使用这个控制元件判断的是调用那这个HTTP请求,HTTP请求中的域名和端口号,变量调用的话,实际上用的是测试计划中的变量
- __jex13函数表达式,在函数助手中选择jex13,然后输入条件自动生成

For each控制器
- 作用:每次使用不同的值重复的发请求,接口是同一个地址,但是请求体可以变
- For each控制器是jmeter为了适配后置处理器中的XX提取器而设置的一个元件
- 添加方法:线程组——添加——逻辑控制器——for each控制器
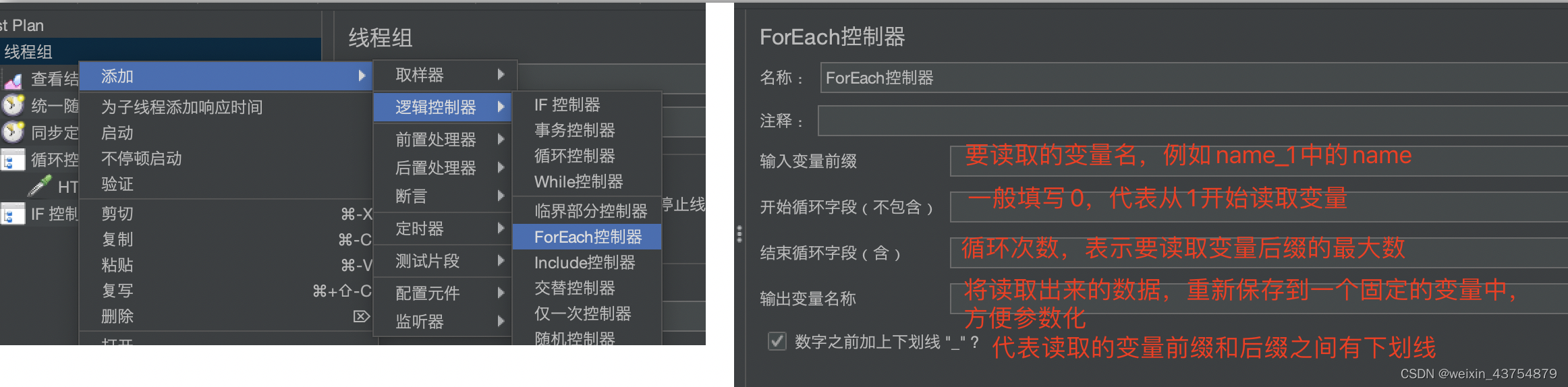
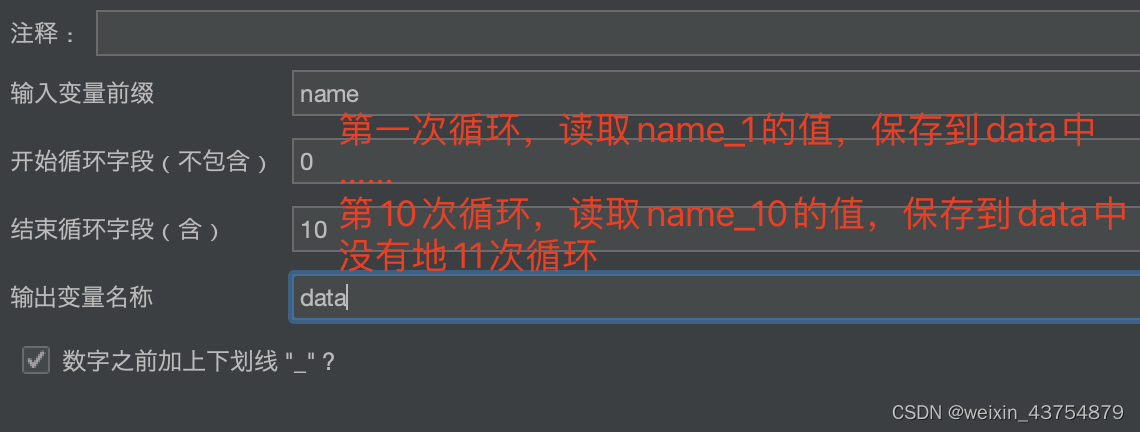
- 这个控制器的用法举个例子:在一个接口中可以返回某用户的多个订单id,但是没有订单详情
仅一次控制器——性能测试中常用
事务控制器
- jmeter中,默认一个取样器的1次完整的请求就是一个事务
- 事务控制器的作用:将多个取样器的完整的请求,当做一个事务;一般用于测试工作流程或者业务场景的性能
- 使用事务控制器的时候,性能测试中,要勾选第一个复选框来合并样本(Generate parent sample)
- 性能测试中,是先做单接口(用不到事务控制器);然后再使用事务控制器合并多个接口测试多接口/工作流程/业务的性能

- 单接口的性能测试,一般情况下是一个线程组下只启用一个接口
-
- 但是需要关联的接口,例如下单,因为要先登录才能进行下一步,这样的话就会出现一个线程组下有至少两个启用的接口
- 上面的场景中**,如果要对下单的接口进行性能测试,就需要将前面的接口(登录)放在一个仅一次控制器中**
聚合报告
- 添加方式:线程组——添加——监听器——聚合报告
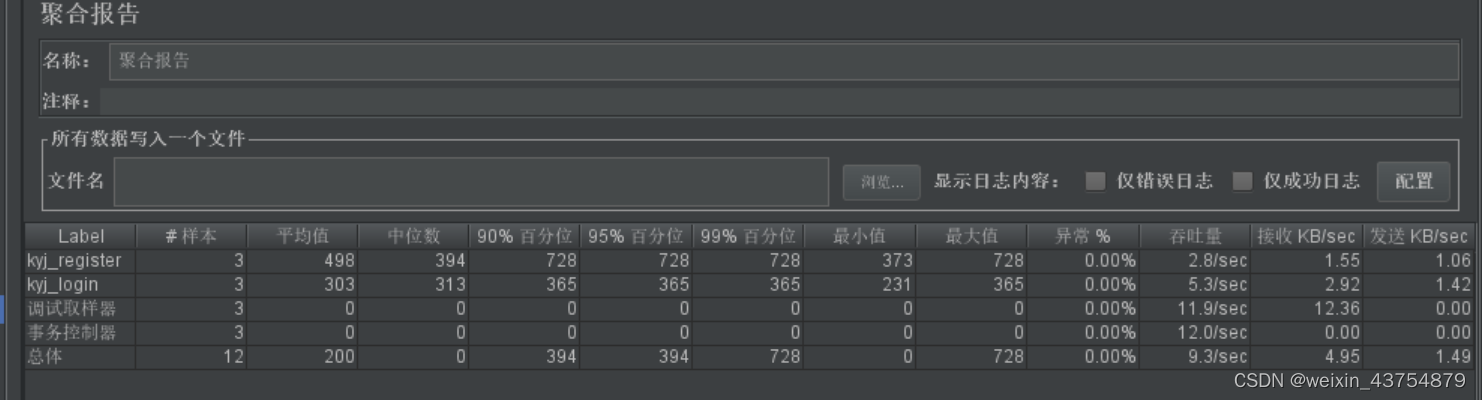
- 聚合报告中的样本值:是一段时间内发起的总请求量
- 响应时间相关的数值,单位是毫秒
- 90%,95%,99%指的是:将响应时间从低到高排序,总序列个数的90%、95%、99%次的响应时间是XX毫秒
-
- 例如一共1000次请求,90%指的是第900次,95%指的是第950次
- 接受和发送,指的是每秒发出/接收到多少请求
- 列表中行:每一行指的是一种事务
原文地址:https://blog.csdn.net/weixin_43754879/article/details/134494513
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_7805.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。