本文介绍: 请注意,在运行代码之前需要安装Keras、scikit-learn、pandas和matplotlib等库,并将时间序列数据保存为CSV文件(文件名为’time_series_data.csv’)。请注意,在运行代码之前需要安装statsmodels、pandas和matplotlib等库,并将时间序列数据保存为CSV文件(文件名为’time_series_data.csv’)。常见的时间序列分析包括时间序列的平稳性检验、自相关性和部分自相关性分析、时间序列模型的建立和预测等。将数据归一化到0-1的范围。
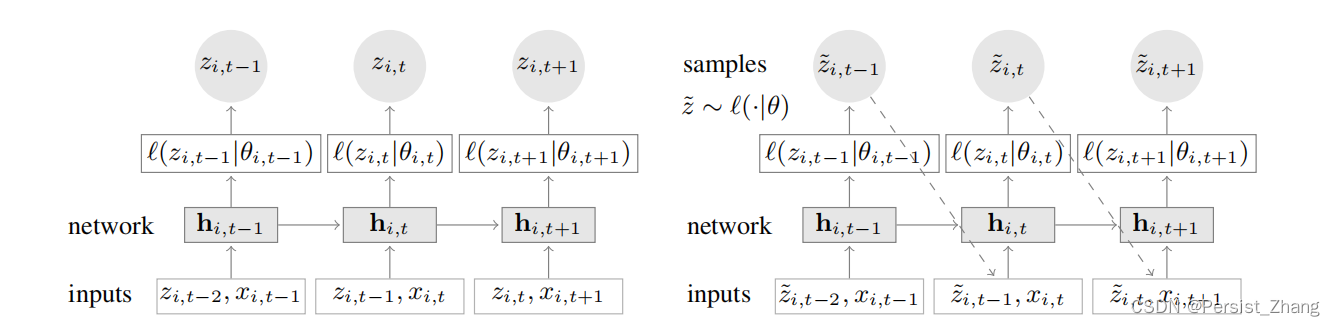
时间序列分析是一种用于建模和分析时间上连续观测的统计方法。 它涉及研究数据在时间维度上的模式、趋势和周期性。常见的时间序列分析包括时间序列的平稳性检验、自相关性和部分自相关性分析、时间序列模型的建立和预测等。
在这个示例中,我们首先导入所需的库,然后使用pd.read_csv函数读取时间序列数据,其中日期列被解析为日期对象,并设置为索引列。接下来,我们使用plt.plot函数绘制了时间序列数据的折线图。
然后,我们使用sm.tsa.adfuller函数对时间序列数据进行平稳性检验。该函数返回ADF统计量和p值,用于判断时间序列数据的平稳性。
接下来,我们使用sm.tsa.seasonal_decompose函数对时间序列进行分解,得到趋势、季节性和残差。然后,使用plt.subplot和plt.plot函数绘制了分解后的时间序列图。
之后,我们使用sm.graphics.tsa.plot_acf和sm.graphics.tsa.plot_pacf函数计算并绘制了时间序列数据的自相关性和部分自相关性图。
如果你想更深入地了解人工智能的其他方面,比如机器学习、深度学习、自然语言处理等等,也可以点击这个链接,我按照如下图所示的学习路线为大家整理了100多G的学习资源,基本涵盖了人工智能学习的所有内容,包括了目前人工智能领域最新顶会论文合集和丰富详细的项目实战资料,可以帮助你入门和进阶。
人工智能交流群(大量资料)

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。