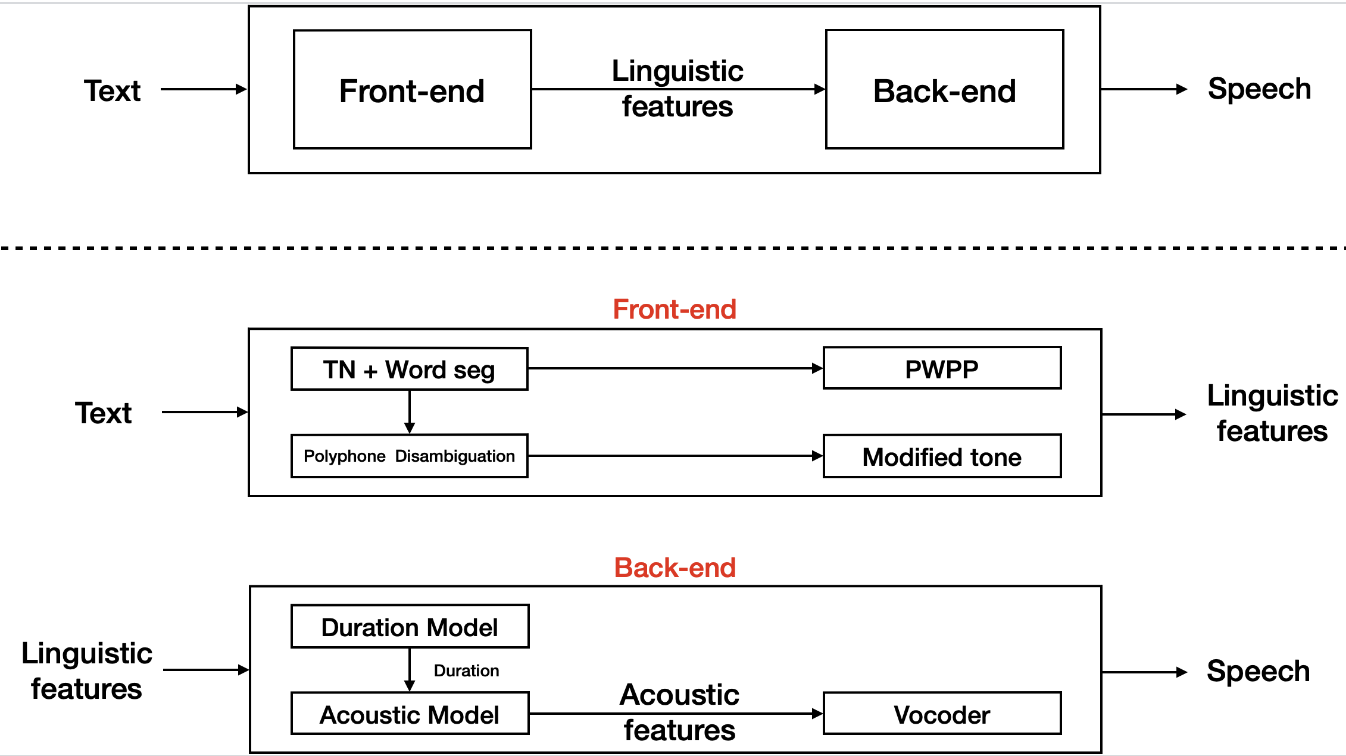
本文介绍: 把 evassh 服务器的 /usr/local 目录下的 spark 安装包通过 SCP 命令上传到 master 虚拟服务器的 /usr/local 目录下。Hadoop 集群在启动脚本时,会去启动各个节点,此过程是通过 SSH 去连接的,为了避免启动过程输入密码,需要配置免密登录。把 master 节点的 spark 安装包分发到 slave1 节点和 slave2 节点(通过 scp 命令)。2、 在 master 复制 master、slave1、slave2 的公钥。输入 jps 命令查看。
Spark 分布式环境安装目前有四种模式:
1.Standalone:Spark 自带的简单群资源管理器,安装较为简单,不需要依赖 Hadoop;
2.Hadoop YARN:使用 YARN 作为集群资源管理,安装需要依赖 Hadoop;
4.Kubernetes:不常用。
本地学习测试我们常用 Standalone 模式,生产环境常使用 YARN 模式。
示例集群信息
配置免密登录
准备Spark安装包
配置环境变量
修改 spark–env.sh 配置文件
修改 slaves 文件
分发安装包
启动spark
验证安装
编程要求
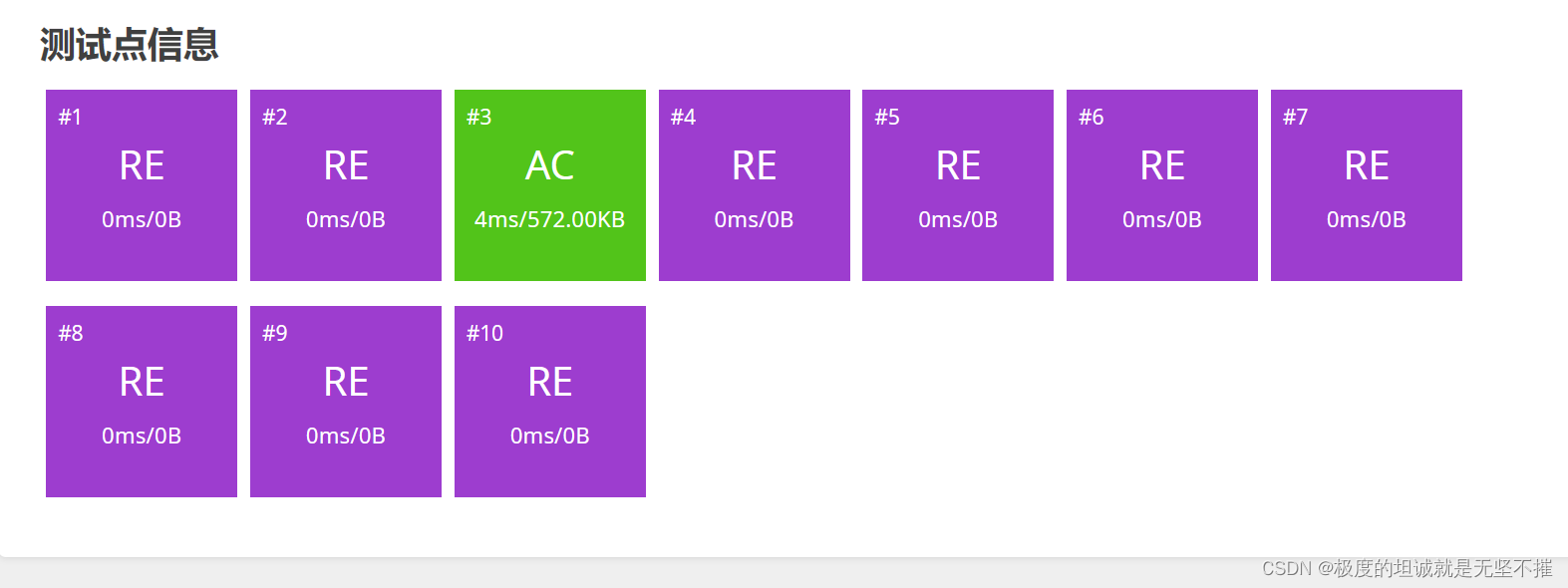
测试说明
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。