本文介绍: *** 默认的负载因子,用来衡量HashMap满的程度。*/负载因子,用来衡量HashMap满的程度。通常,默认负载因子(0.75)在时间和空间成本之间提供了一个很好的权衡。负载因子越大则散列表的装填程度越高,减少空间开销,但会增加查找成本。负载因子越小则链表中的数据量就越稀疏,此时会对空间造成烂费,但是此时索引效率高。试想一下,如果我们把负载因子设置成1,容量使用默认初始值16,那么表示一个HashMap需要在”满了”之后才会进行扩容。
HashMap源码解析-jdk1.8(三)
负载因子loadFactor为什么是0.75?
负载因子,用来衡量HashMap满的程度。通常,默认负载因子(0.75)在时间和空间成本之间提供了一个很好的权衡。负载因子越大则散列表的装填程度越高,减少空间开销,但会增加查找成本。负载因子越小则链表中的数据量就越稀疏,此时会对空间造成烂费,但是此时索引效率高。
试想一下,如果我们把负载因子设置成1,容量使用默认初始值16,那么表示一个HashMap需要在”满了”之后才会进行扩容。那么在HashMap中,最好的情况是这16个元素通过hash算法之后分别落到了16个不同的桶中,否则就必然发生哈希碰撞。而且随着元素越多,哈希碰撞的概率越大,查找速度也会越低。
我们假设一个bucket空和非空的概率为0.5,我们用s表示容量,n表示已添加元素个数。用s表示添加的键的大小和n个键的数目。根据二项式定理,桶为空的概率为:
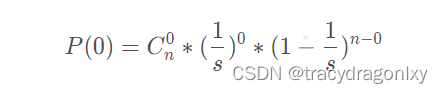

HashMap的长度为什么是2的幂次方
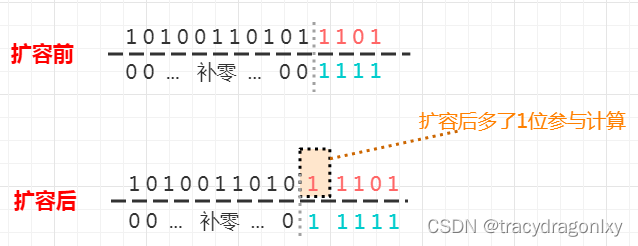
1. 与取余等价的算法


2. 扩容时方便定位
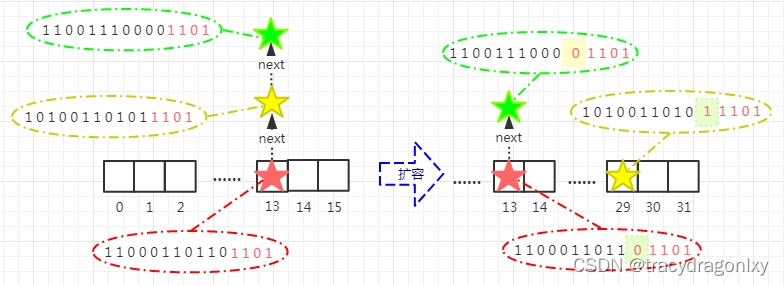
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。