CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION (Paper reading)
Ziwei Luo, Uppsala University, ICLR under review(6663), Cited:None, Stars: 350+, Code, Paper.
1. 前言
像CLIP这样的视觉语言模型已经显示出对零样本或无标签预测的各种下游任务的巨大影响。然而,当涉及到图像恢复等低水平视觉时,由于输入损坏,它们的性能会急剧下降。在本文中,我们提出了一种退化感知视觉语言模型(DA-CLIP),以更好地将预训练的视觉语言模型转移到低级视觉任务中,作为图像恢复的多任务框架。更具体地说,DA-CLIP训练一个额外的控制器,该控制器调整固定的CLIP图像编码器以预测高质量的特征嵌入。通过交叉关注将嵌入集成到图像恢复网络中,我们能够引导模型学习高保真度图像重建。控制器本身还将输出与输入的实际损坏相匹配的退化特征,从而为不同的退化类型生成自然分类器。此外,我们构建了一个具有合成字幕的混合退化数据集,用于DA-CLIP训练。我们的方法在退化特定和统一的图像恢复任务上都取得了最先进的性能,显示了用大规模预训练的视觉语言模型促进图像恢复的有前途的方向。
2. 整体思想
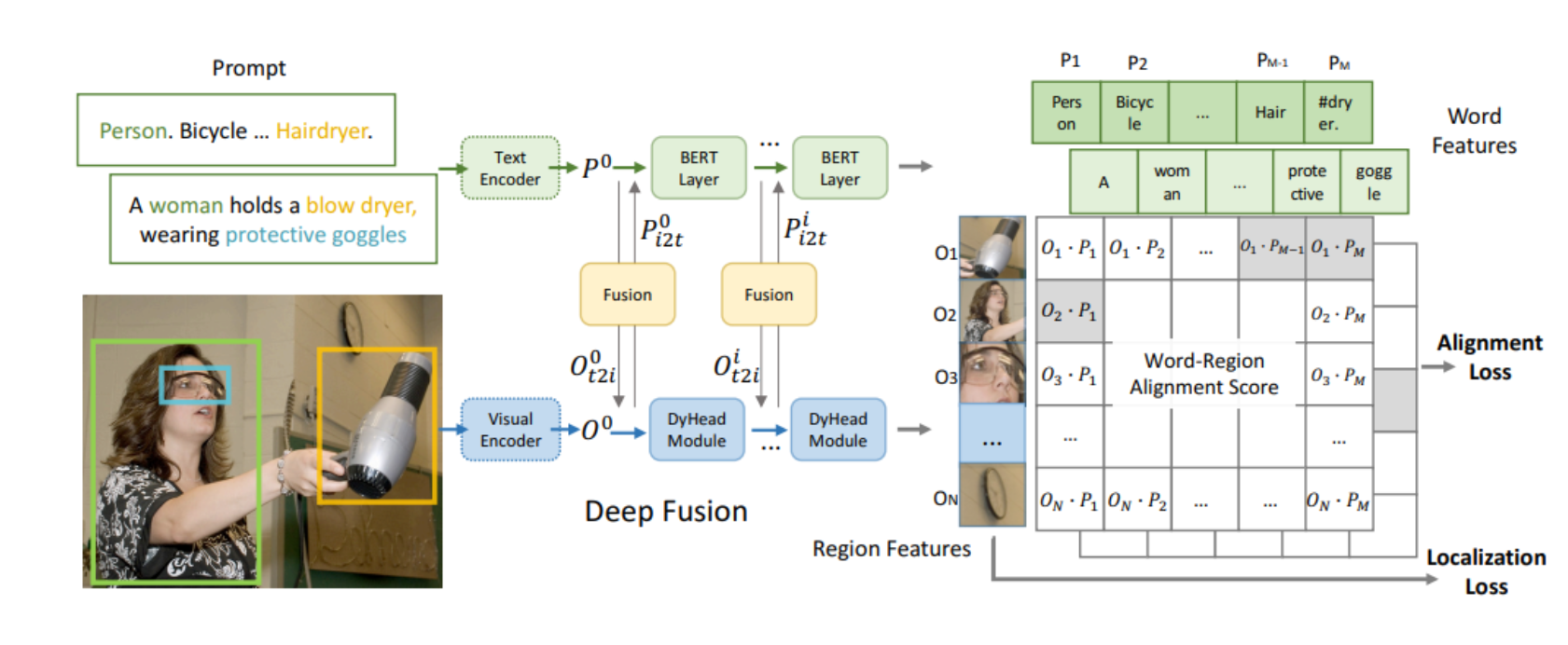
ALL in one的图像复原模型,可以用分类器对不同输入图像做分类,然后分类得到的一些输出作为条件来指导One这个模型对特定类型任务复原。这篇文章的思想也是一样的。他们使用类似于ControlNet的方法,对CLIP做微调,使CLIP可以根据输入LQ图像,得到HQ的内容编码和预测LQ的降质类型编码。这两个编码作为其他模型的条件实现All in one。思想是很老旧的,方法也是ControlNet的,但是确实work。具体的其他疑问见第6小节。
3. 介绍

现有的大规模预训练的视觉语言模型(VLM)对图像恢复(IR)等low-level视觉任务的影响有限,可能是因为它们没有捕捉到“模糊”和“噪声”等图像退化类型之间的细粒度差异。因此,现有的VLM经常使图像特征与退化文本不对齐。这并不奇怪,考虑到VLM通常在不同的网络规模数据集上进行训练,而大多数图像恢复模型是在相对较小的数据集上训练的,这些数据集是为特定任务策划的,没有相应的图像-文本对。
传统图像恢复方法通常只是简单地学习逐像素生成图像,而不利用任务知识,这通常需要对特定退化类型的同一模型进行重复训练。然而,最近的一项工作集中在统一图像恢复上,在混合退化数据集上训练单个模型,并隐式地对恢复过程中的退化类型进行分类。虽然结果令人印象深刻,但它们仍然局限于少数退化类型和与之相关的特定数据集。特别是,它们没有利用VLM中嵌入的大量信息。
在本文中,我们将大规模预训练的视觉语言模型CLIP与图像恢复网络相结合,提出了一个可应用于退化特定和统一图像恢复问题的多任务框架。具体来说,为了解决损坏的输入和干净的captions之间的特征不匹配问题,我们提出了一种图像控制器(Image Controller),该控制器调整VLM的图像编码器,以输出与干净的caption对齐的高质量(HQ)内容嵌入。同时,控制器本身也预测退化嵌入以匹配真实退化类型。这种新的框架,我们称之为退化感知CLIP(DA-CLIP),将VLM的人类级知识融入到通用网络中,从而提高图像恢复性能并实现统一的图像恢复。