前言
最近在复习django的时候,发现了一个有趣的问题,解决了之后特意记录下来,以供以后参考。
一、问题
相信大家使用django的时候,被其DRF的强大功能所折服,因为它能通过简单的代码就能帮助我们实现增删改查等最简单的操作。我的demo代码如下:
模型类代码,models.py
from django.db import models
class StudentInfo(models.Model):
name = models.CharField(max_length=10, verbose_name='姓名')
sex = models.CharField(max_length=1, verbose_name='性别')
from_class = models.ForeignKey(ClassInfo, on_delete=models.CASCADE)
from rest_framework import serializers
from demo import models
class StudentInfoSerializer(serializers.ModelSerializer):
class Meta:
model = models.StudentInfo
fields ="__all__"
from rest_framework.viewsets import ModelViewSet
from .models import StudentInfo
from .serializers import StudentInfoSerializer
class DemoView(ModelViewSet):
queryset = StudentInfo.objects.all()
serializer_class = StudentInfoSerializer
from rest_framework.routers import SimpleRouter, DefaultRouter
from .views import DemoView
urlpatterns = []
# demo_route = SimpleRouter()
demo_route = DefaultRouter()
demo_route.register("demo", DemoView, basename="demo")
urlpatterns += demo_route.urls
最后在项目的主路由里面添加路径即可(需要在settings.py里面注册app):
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path("admin/", admin.site.urls),
path("user/", include("user.urls")),
path("", include("demo.urls"))
]
效果:
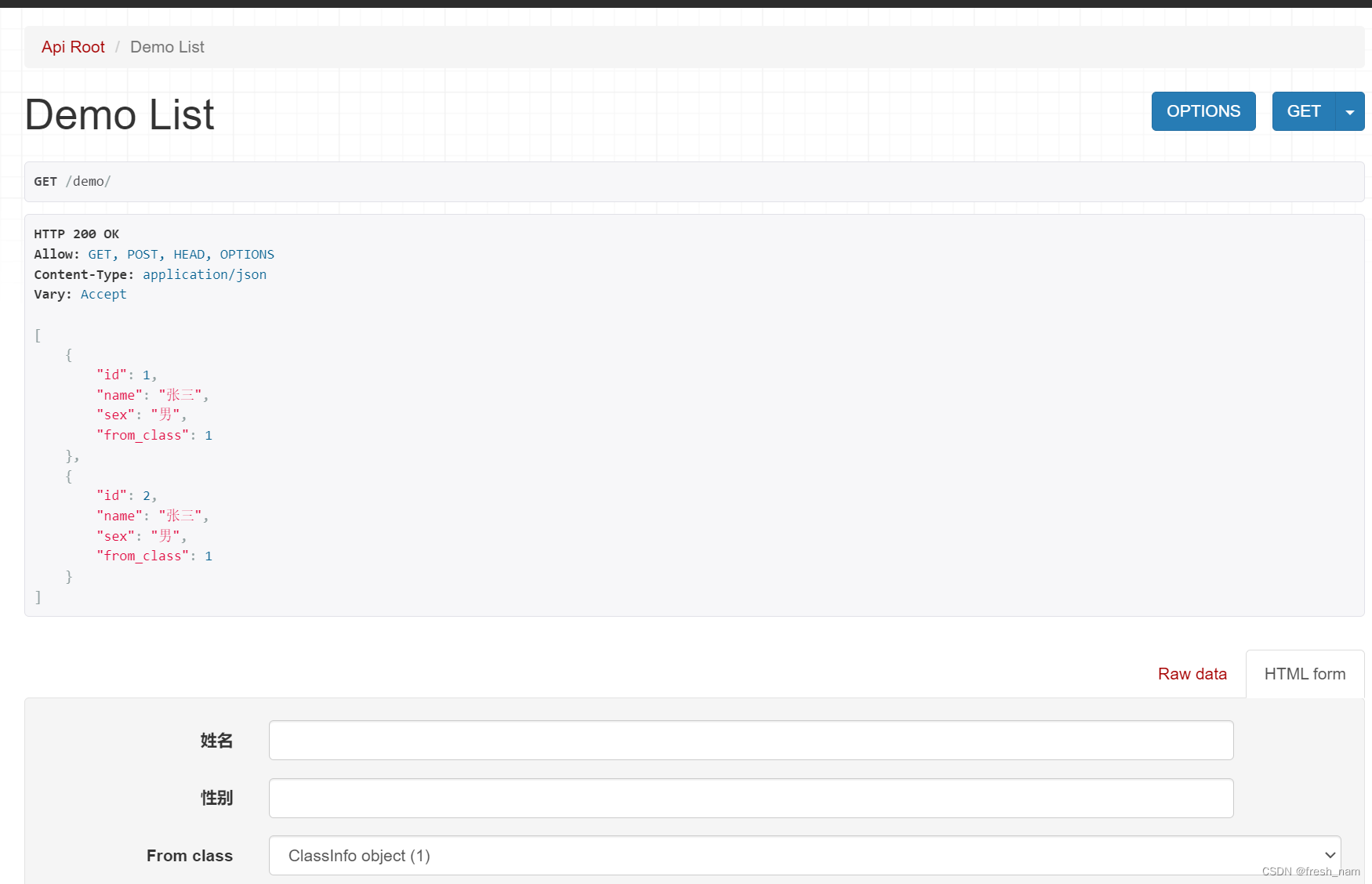
但是,这样会出现一个问题,就是无法控制序列化结果显示的字段。例如,在同一个项目中,可能会出现多个场景,一个场景只需要用户的name和sex字段,一个场景只需要用户的name字段,一个场景则需要用户的全部字段,按照以上方法就需要设置三个序列化器了,显然不符合实际应用。那么有没有办法可以兼顾便捷和灵活呢?
二、解决
解决方法很简单,重写序列化器的__init__()方法即可:
serializers.py
# 动态修改fileds字段
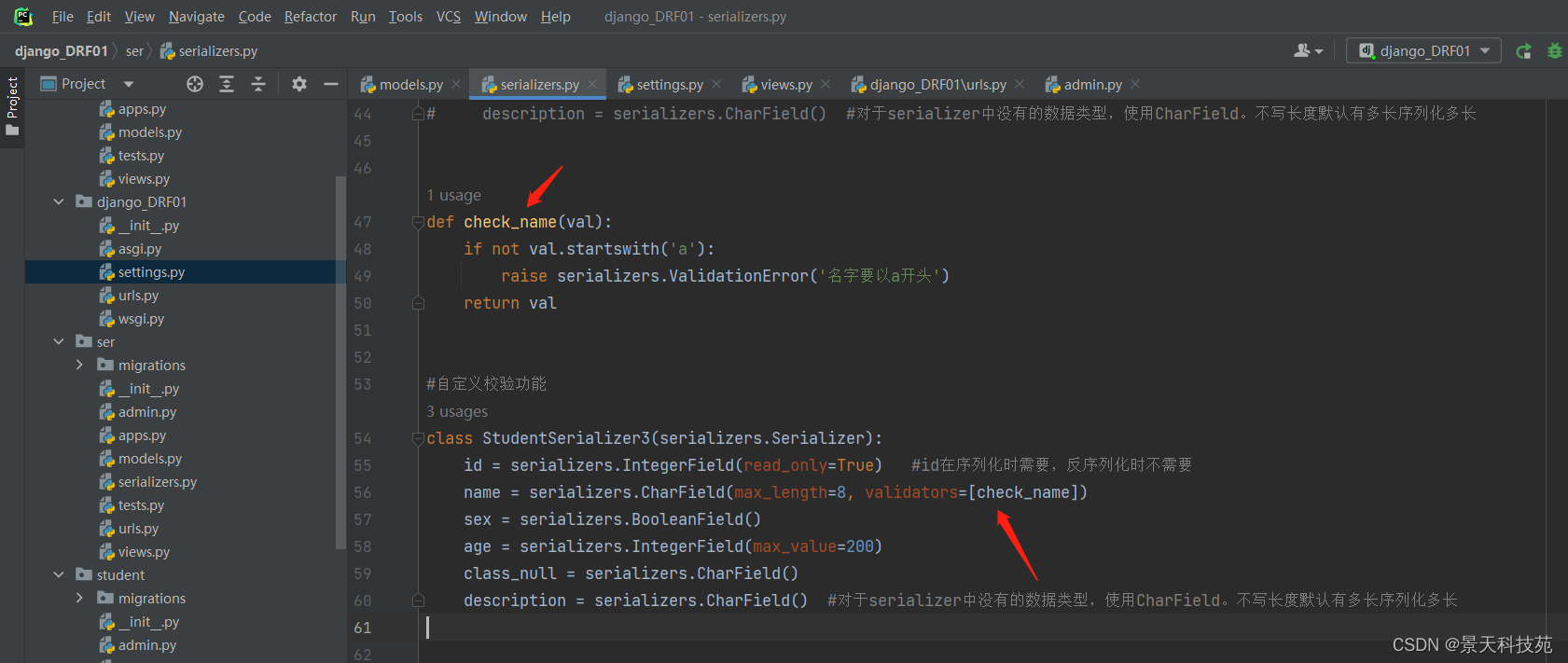
class StudentInfoSerializer(serializers.ModelSerializer):
"""
此处的`fields`字段是用来替换上面Serializer内部Meta类中指定的`fields`属性值
"""
def __init__(self, *args, **kwargs):
# 在super执行之前
# 将传递的`fields`中的字段从kwargs取出并剔除,避免其传递给基类ModelSerializer
# 注意此处`fields`中在默认`self.fields`属性中不存在的字段将无法被序列化 也就是`fields`中的字段应该是`self.fields`的子集
fields = kwargs.pop('fields', None)
super(StudentInfoSerializer, self).__init__(*args, **kwargs)
if fields is not None:
# 从默认`self.fields`属性中剔除非`fields`中指定的字段(两个集合相减,会提出多余的元素)
allowed = set(fields)
existing = set(self.fields.keys())
for field_name in existing - allowed:
self.fields.pop(field_name)
class Meta:
model = models.StudentInfo
fields ="__all__"
以上代码的原理也很简单,首先获取传入的fields参数(即你想要的字段);然后使用序列化器原有的字段减去你想要的字段,就获取了多余的字段;最后,循环遍历多余的字段,将它们从原有的字段中一个一个剔除。
为了更好的展示结果,我这里自定义了三个路径:
views.py
from django.shortcuts import render
# Create your views here.
from rest_framework.decorators import action
from rest_framework.response import Response
from rest_framework.viewsets import ModelViewSet
from .models import StudentInfo
from .serializers import StudentInfoSerializer
class DemoView(ModelViewSet):
queryset = StudentInfo.objects.all()
serializer_class = StudentInfoSerializer
@action(url_path="all_fields", methods=["GET"], detail=False)
def all_fields(self, request):
user_data = StudentInfo.objects.all()
serializer = StudentInfoSerializer(instance=user_data, many=True)
return Response(serializer.data)
@action(url_path="name_sex", methods=["GET"], detail=False)
def name_sex(self, request):
user_data = StudentInfo.objects.all()
serializer = StudentInfoSerializer(instance=user_data, fields=("name", "sex"), many=True)
return Response(serializer.data)
@action(url_path="name_fromclass", methods=["GET"], detail=False)
def name_fromclass(self, request):
user_data = StudentInfo.objects.all()
serializer = StudentInfoSerializer(instance=user_data, fields=("name", "from_class"), many=True)
return Response(serializer.data)
效果如下:
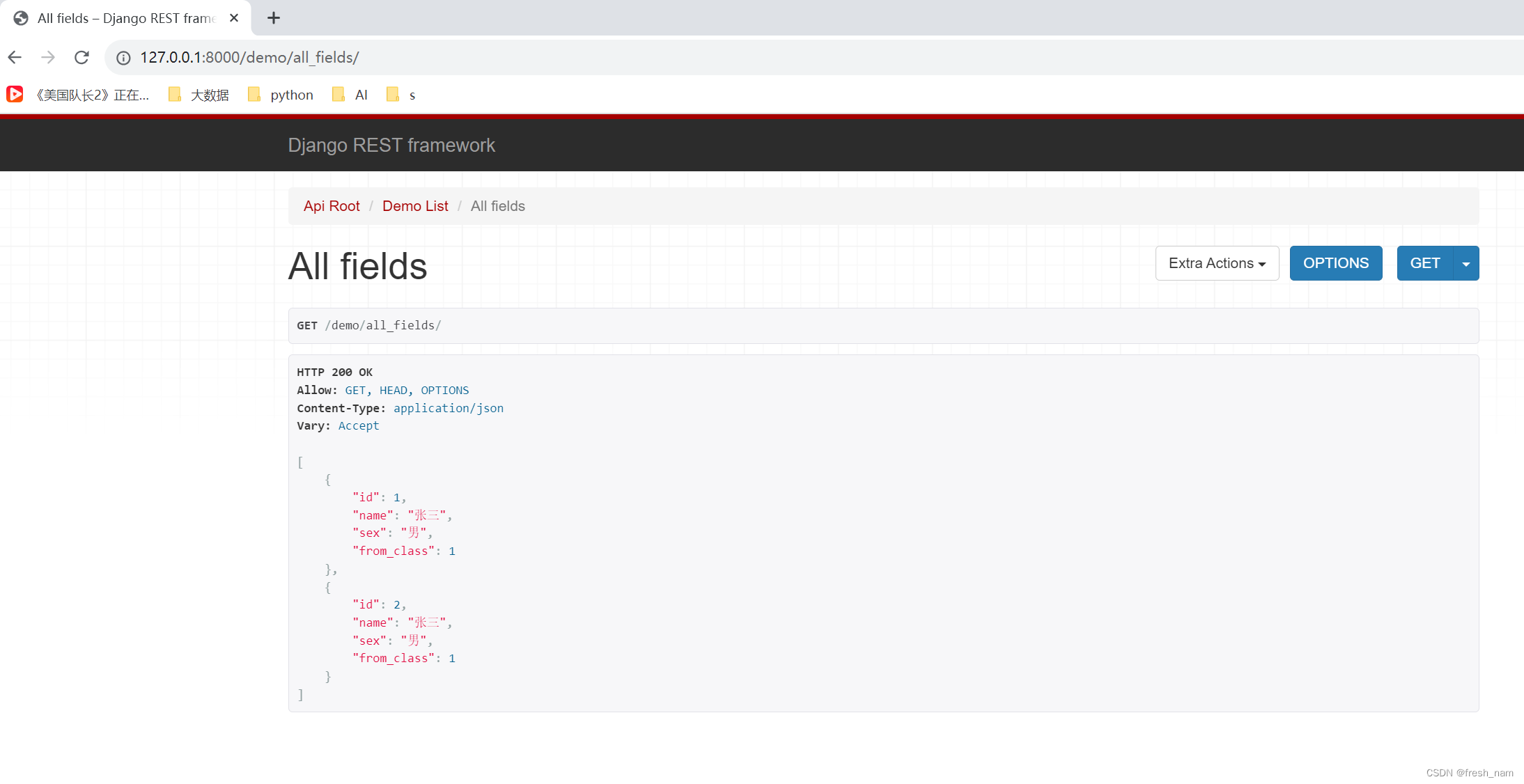
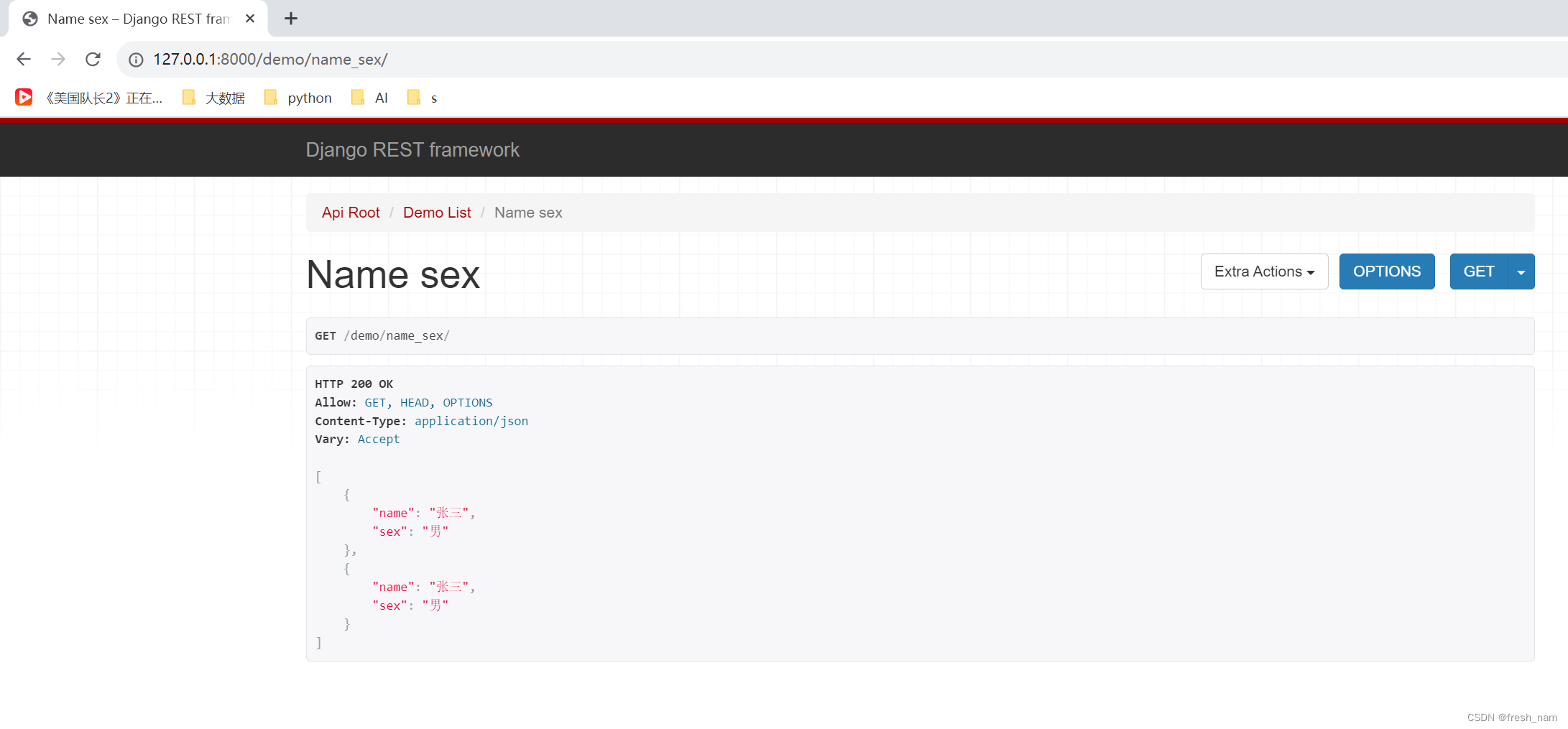
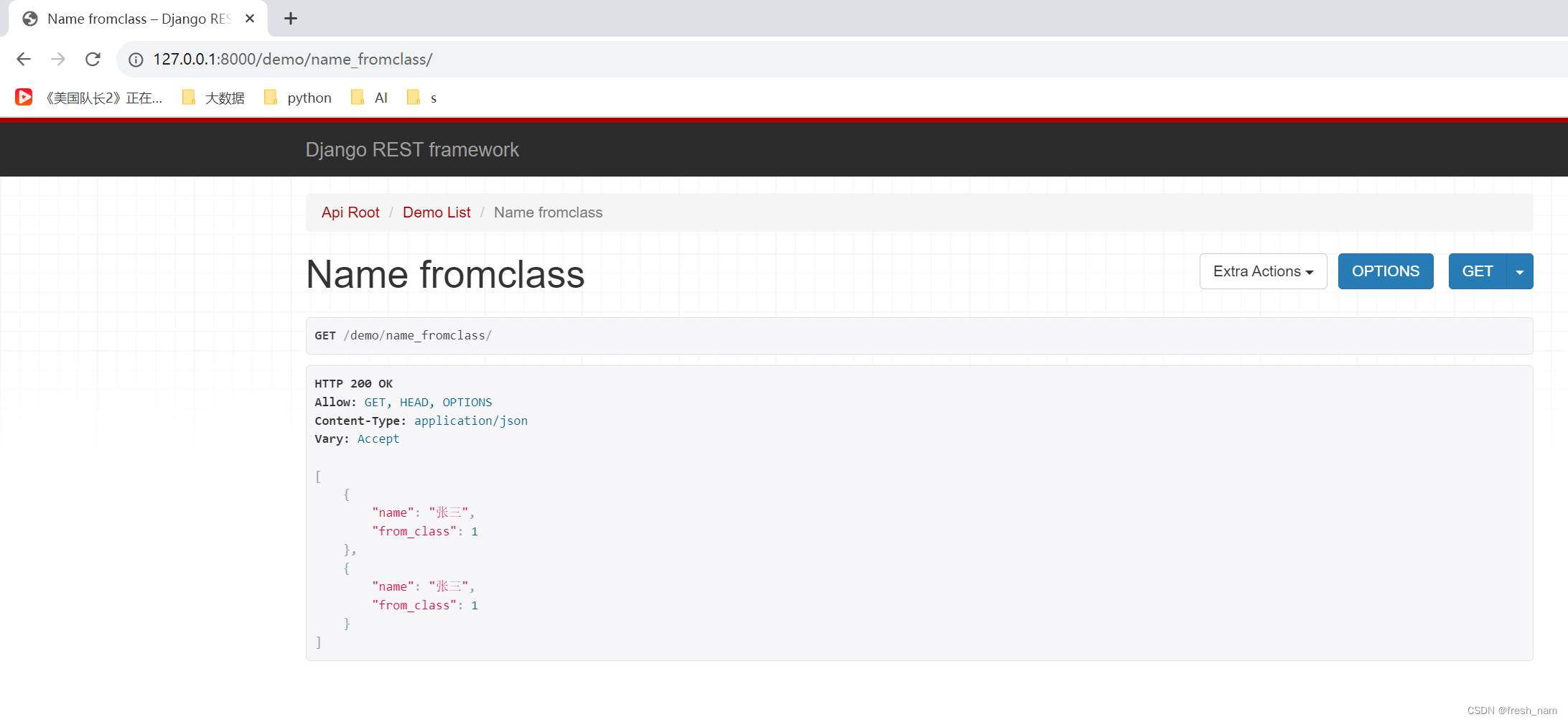
可以看出,根据传入的fields的不同,返回不同的结果。
原文地址:https://blog.csdn.net/fresh_nam/article/details/134526438
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_8377.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!