本文介绍: GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以找到关于GPT/AIGC/LLM最新的研究论文、博客文章、实用的工具和预设指令(Prompts)。

GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以找到关于GPT/AIGC/LLM最新的研究论文、博客文章、实用的工具和预设指令(Prompts)。现为了更好地知悉近一周的贡献内容,现总结如下。
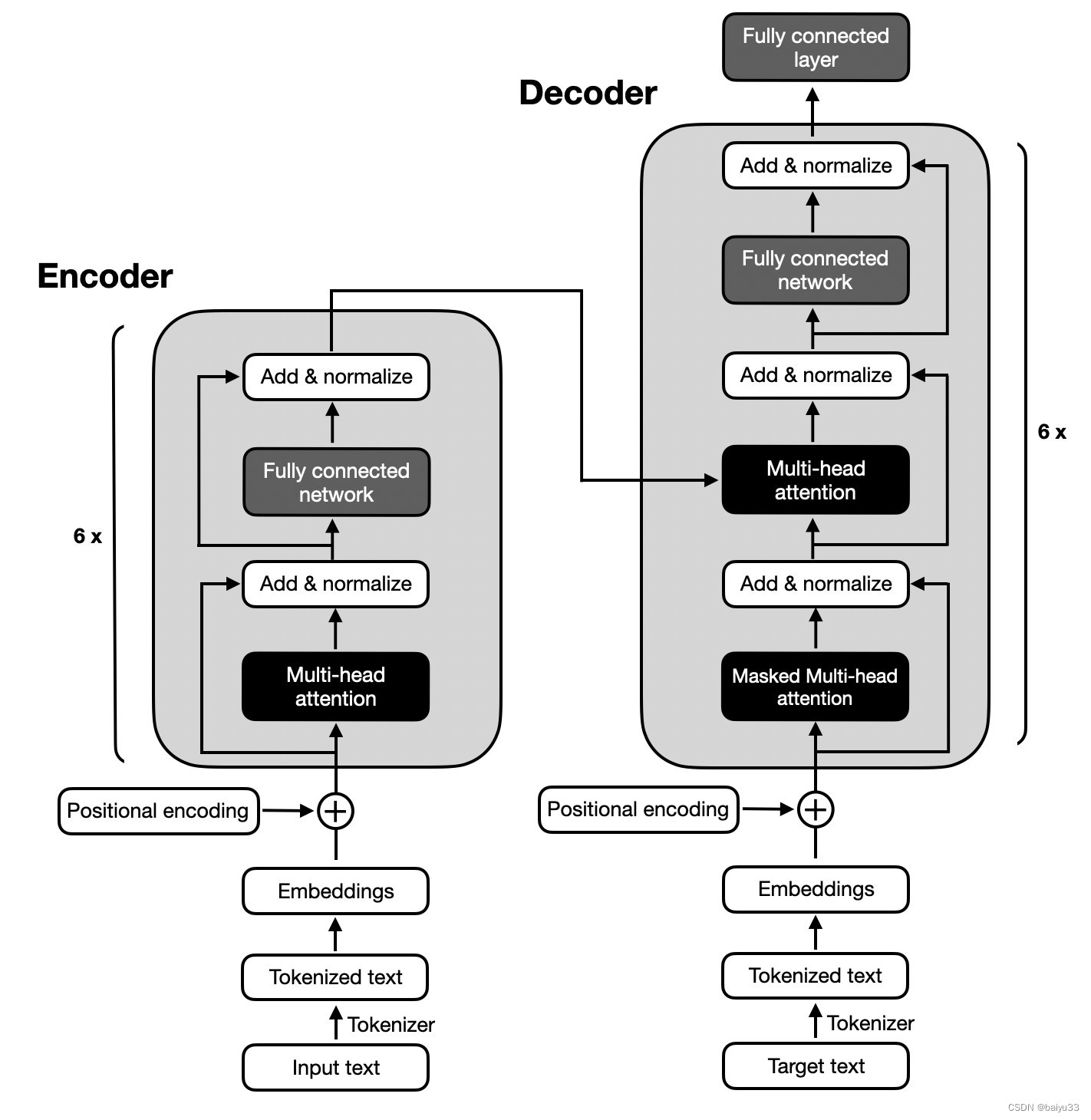
Security Papers
开源大模型
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。