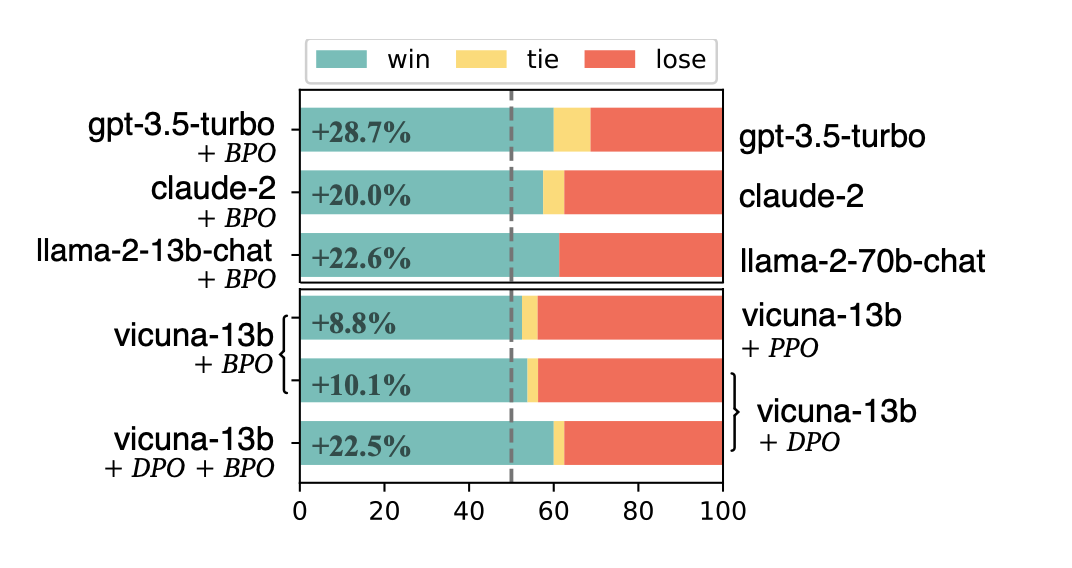
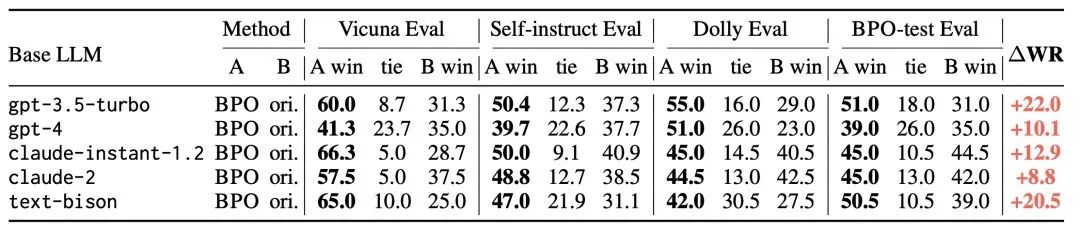
本文介绍: 在 vicuna-7b 和 vicuna-13b 上,使用 BPO 对齐的模型超过了常用的反馈学习方法—— PPO(Proximal Policy Optimization) 和 DPO(Direct Preference Optimization)的效果,并且能够和这些方法相结合进一步提升模型效果。使用这些反馈数据来引导大型模型识别用户喜欢的回复和不喜欢的回复,基于这些特征,再利用模型优化原始的用户输入,以期得到更符合用户喜好的模型输出;

论文题目:《Black-Box Prompt Optimization: Aligning Large Language Models without Model Training》
论文链接:https://arxiv.org/abs/2311.04155
github地址:https://github.com/thu-coai/BPO
BPO背景介绍
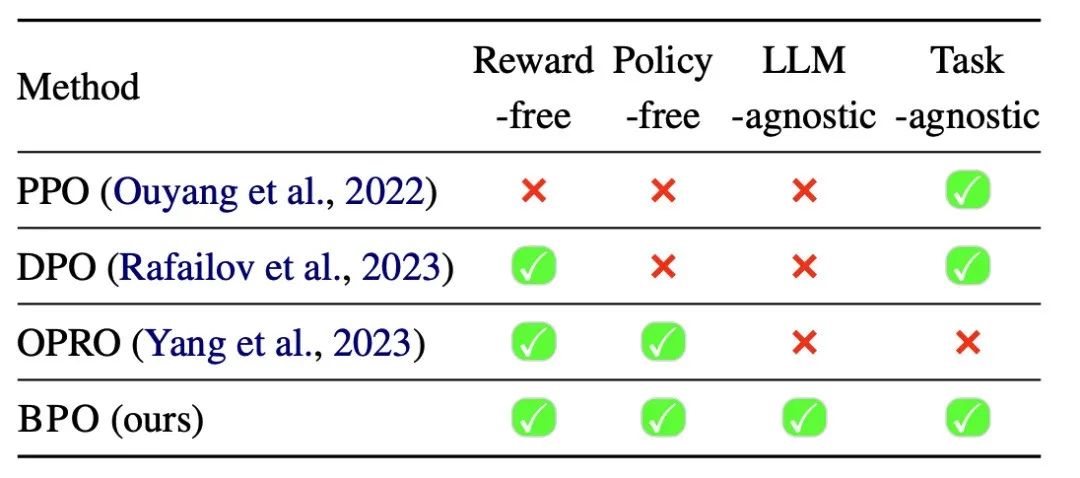
最近,大型语言模型(LLM)在各种应用中都取得了显著的成功,比如文本生成,文生图大模型等。然而,这些模型往往与人类意图不太一致,这就需要对其进行额外的处理,即对齐问题。为了使LLM更好地遵循用户指令,现有的对齐方法(比如RLHF、RLAIF和DPO)主要侧重于对LLM进行进一步的训练,然而这些对齐方法有如下缺点:
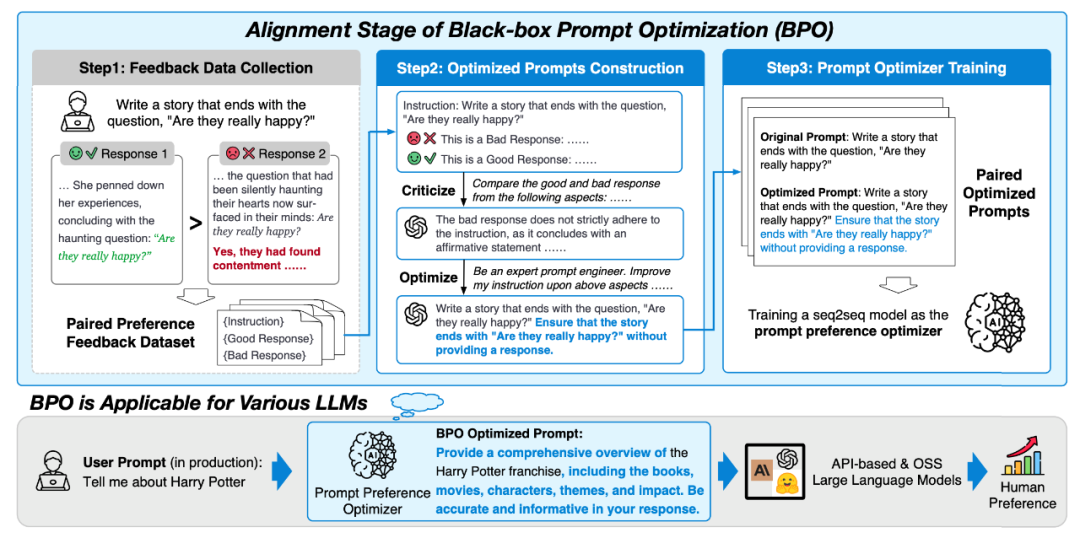
BPO方法原理
BPO与其他对齐方法的对比
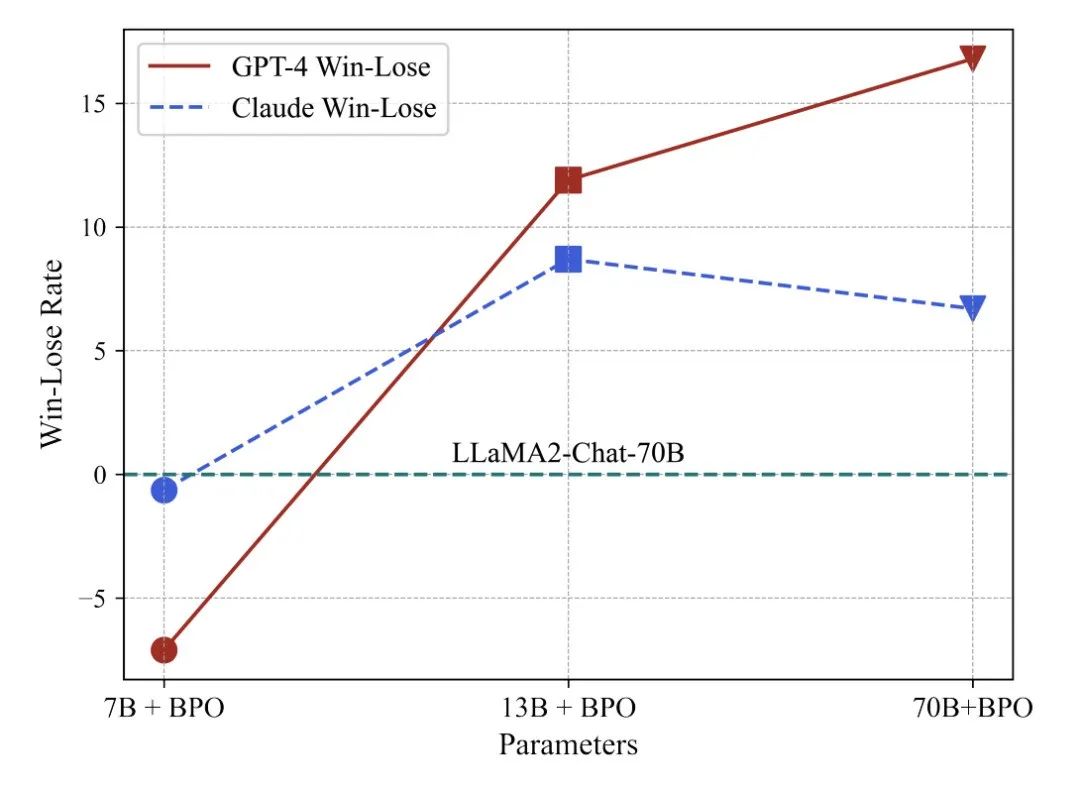
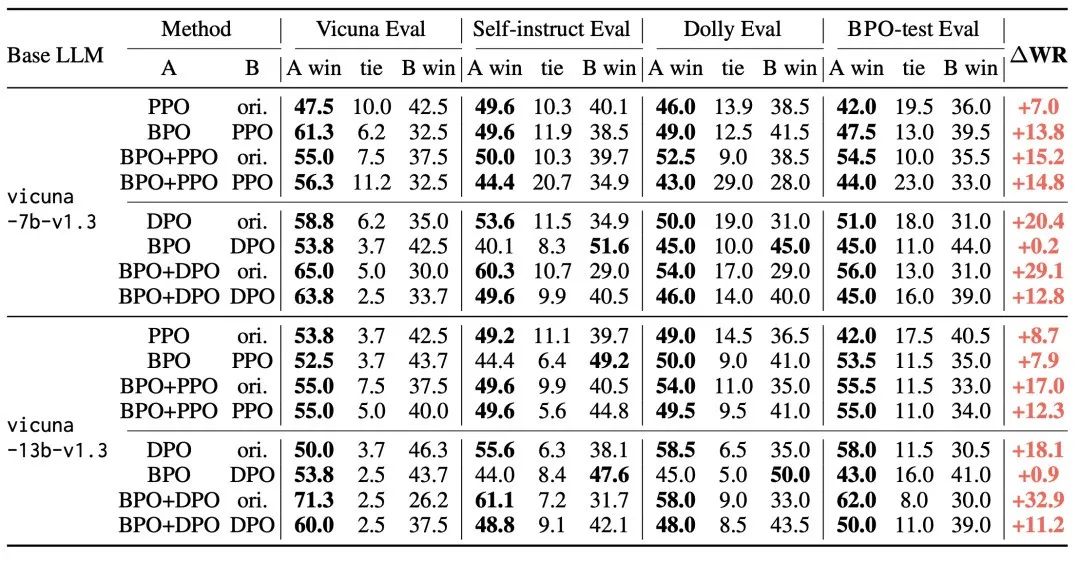
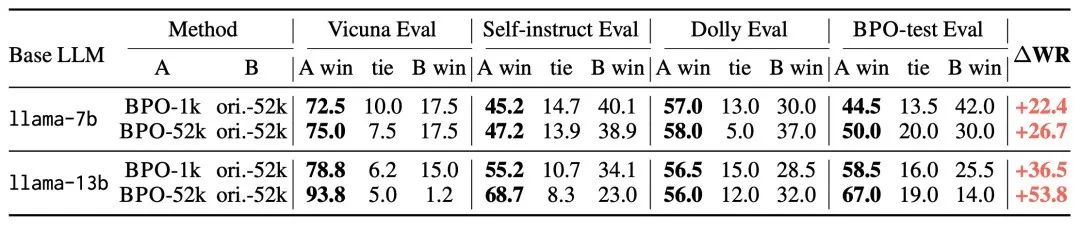
BPO实验效果
BPO优化前后Prompt的对比

参考文献:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






