本文介绍: ChatGPT全称为Chat Generative Pre–trained Transformer,一个基于深度学习的大型语言模型,其模型结构使用了Transformer网络。这个网络可以从输入的文本中学习语言的规律和模式,并用这些规律和模式来预测下一个单词或字符。在chatGPT的训练过程中,chatGPT接受了海量的文本数据,这些数据包括各种来源,例如维基百科、新闻文章、小说、网页等等。
自从2022年11月30日发布以来,ChatGPT一直占据着科技届的头条位置,随着苹果的创新能力下降,ChatGPT不断给大家带来震撼,2023年11月7日,首届OpenAI开发者大会在洛杉矶举行,业界普遍认为,OpenAI的开发者大会可能会替代苹果发布会,成为AI时代最引人注目的“科技春晚”。
但ChatGPT的背后到底是如何运作的,它的超强能力究竟是如何形成的?它有什么特别之处?它的竞争对手能超越它吗?这一系列的问题正是本文所要讨论的。
什么是ChatGPT?
ChatGPT全称为Chat Generative Pre–trained Transformer,一个基于深度学习的大型语言模型,其模型结构使用了Transformer网络 。这个网络可以从输入的文本中学习语言的规律和模式,并用这些规律和模式来预测下一个单词或字符。

在chatGPT的训练过程中,chatGPT接受了海量的文本数据,这些数据包括各种来源,例如维基百科、新闻文章、小说、网页等等。这些庞大的数据集被用来形成一个模仿人脑的深度学习神经网络,在学习过程中,chatGPT试图学习这些数据中的语言规则和模式,预测文本序列中的下一个单词或字符,以提高自己的准确性。
Transformer 架构



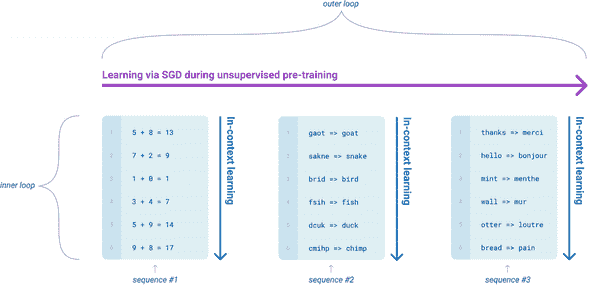
预训练与人类反馈强化学习 (RLHF)



训练数据集


自然语言处理(NLP)
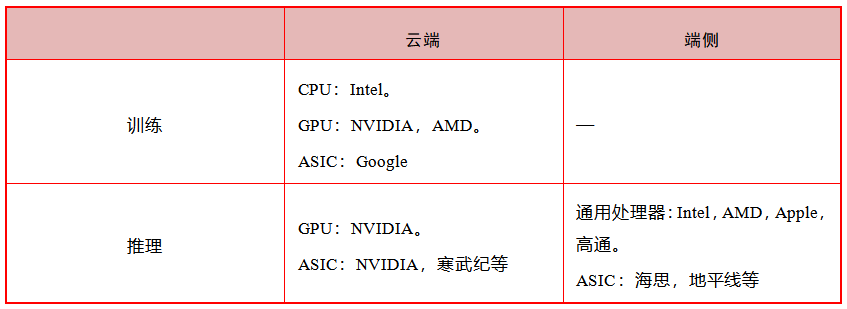
算力

问题与期待
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。