什么是 bigkey?
简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
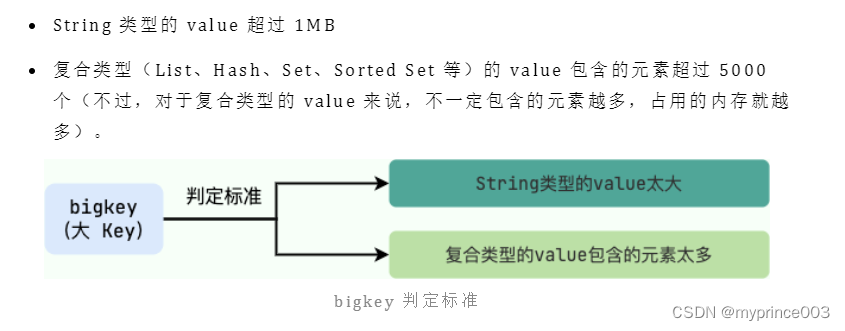
bigkey 是怎么产生的?有什么危害?
bigkey 通常是由于下面这些原因产生的:
程序设计不当,比如直接使用 String 类型存储较大的文件对应的二进制数据。
对于业务的数据规模考虑不周到,比如使用集合类型的时候没有考虑到数据量的快速增长。
未及时清理垃圾数据,比如哈希中冗余了大量的无用键值对。
bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。
在 Redis 常见阻塞原因总结[1]这篇文章中我们提到:大 key 还会造成阻塞问题。具体来说,主要体现在下面三个方面:
客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
工作线程阻塞:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
大 key 造成的阻塞问题还会进一步影响到主从同步和集群扩容。
综上,大 key 带来的潜在问题是非常多的,我们应该尽量避免 Redis 中存在 bigkey。
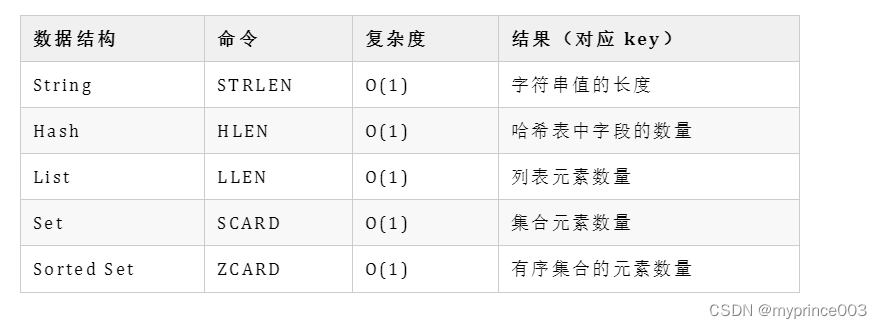
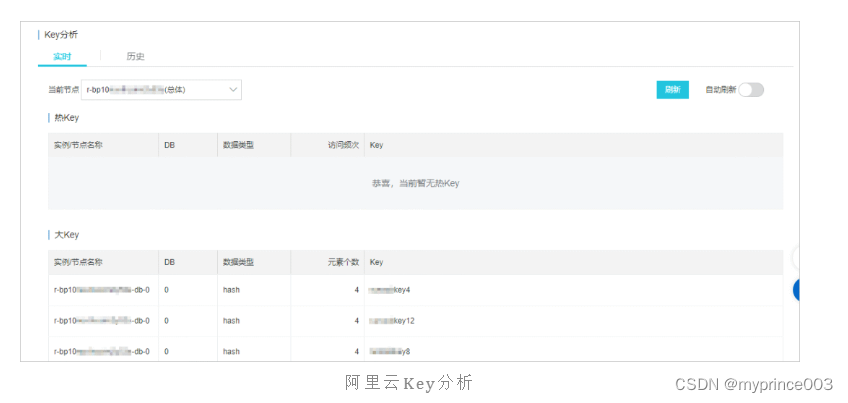
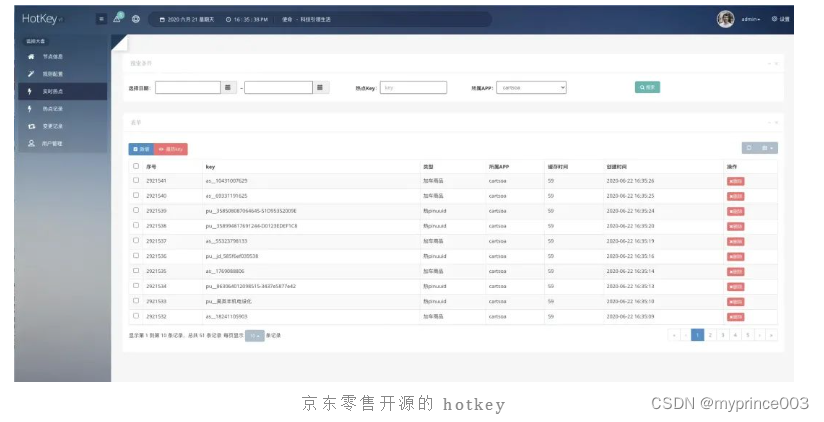
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






