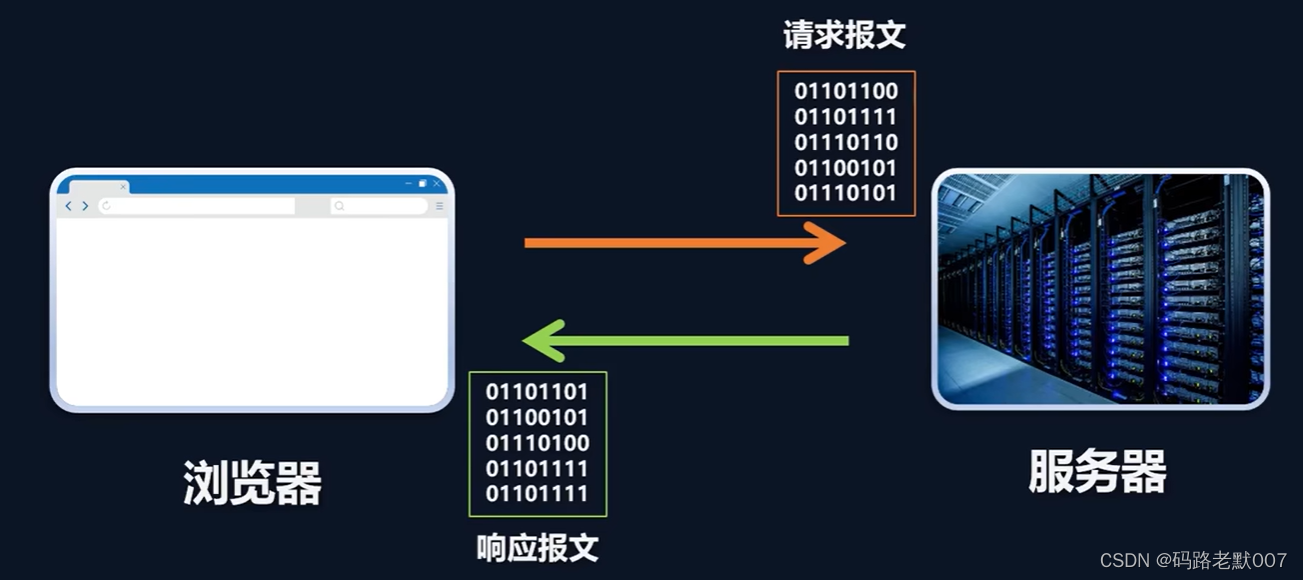
本文介绍: 在互联网时代,图片是信息传递和展示的重要组成部分,而提取网页中的图片数据对于一些项目和需求来说尤为重要。本文将详细介绍如何使用Node.js编写爬虫程序,实现网页图片的批量爬取,帮助您轻松获得所需的图片数据,并揭示一些实用技巧和注意事项。三、运行程序与注意事项。
在互联网时代,图片是信息传递和展示的重要组成部分,而提取网页中的图片数据对于一些项目和需求来说尤为重要。本文将详细介绍如何使用Node.js编写爬虫程序,实现网页图片的批量爬取,帮助您轻松获得所需的图片数据,并揭示一些实用技巧和注意事项。
一、准备工作
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。