本文介绍: ALL是全表扫描,就是啥索引也不用。index是对索引表进行全扫描,这样做的好处是不再需要对数据进行排序,但是开销依然很大。—以上是效果不咋样的,下面开始就是能发挥出索引优势的级别了—range是用到范围了一般是where中有> < in between了,能利用上索引。ref 类型表示采用了非唯一索引,或者是唯一索引的非唯一性前缀,返回数据返回可能是多条。因为虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。
前缀索引
这个操作是为了减少索引长度,即占用空间的。这样一个页可以多存一些索引,查找时候就会更快了。但是前缀索引有俩缺点,一个是ORDER BY或GROUP BY时候没法用,另一个是没法用做覆盖索引(因为索引本来自己都不全,没法提供完整信息,还是需要回表的)
覆盖索引
主键索引最好是自增的
避免增加数据时候,主键插入在B+树的中间,导致树的复杂结构变化。自增的直接插在最后就行。另外主键别太长,因为它是作为value存到二级索引的B+树叶子节点的,太长了占用空间。
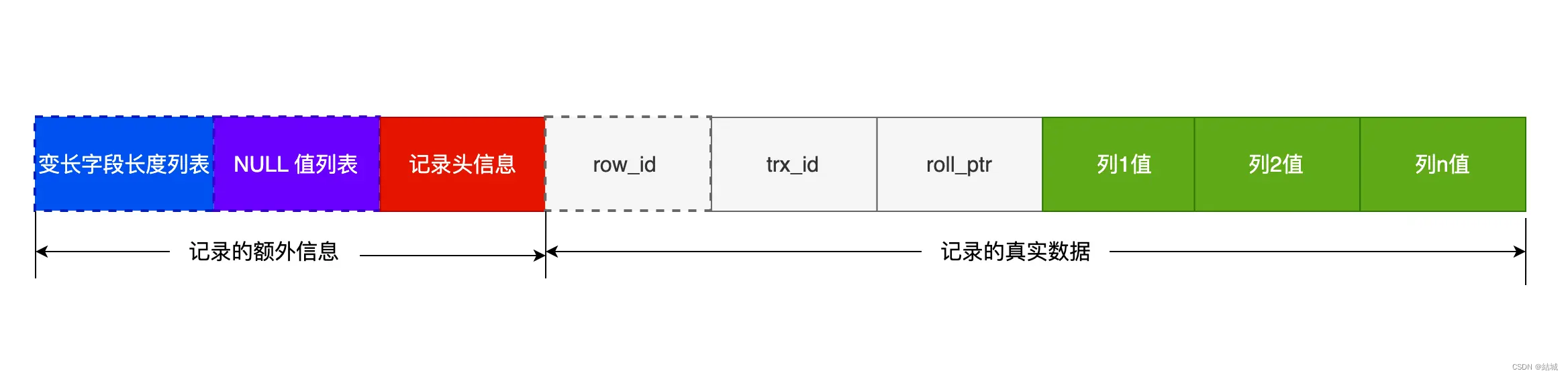
索引最好设置为 NOT NULL
两个原因,一个是NULL会让优化器做选择适合增加复杂度,因为涉及到运算时候,NULL太复杂,比如进行索引统计时,count 会省略值为NULL 的行;另一个是NULL让行数据平白无故要增加记录,至少一个字节,如下图
防止索引失效
索引会失效的情况介绍在这篇文章了,具体用没用到索引,用了啥索引可以用EXPLAIN来看

对于执行计划,参数有:
type 字段就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。