本文介绍: sklearn.model_selection.train_test_split:用于将数据集划分成训练集和测试集。sklearn.model_selection.GridSearchCV:用于对模型进行参数调优。sklearn.neural_network.MLPClassifier:多层感知机分类器。matplotlib.pyplot:用于绘制图表,提供了多种绘图函数和样式设置选项。sklearn.linear_model.Perceptron:感知机模型。
要使用感知机,我们首先要引入头文件,以下是感知机用的到头文件:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neural_network import MLPClassifier
解释一下这些头文件的功能:
pandas:用于数据处理和分析,提供了DataFrame对象来处理表格型数据。
numpy:用于数值计算,提供了高效的数组操作和数学函数。
matplotlib.pyplot:用于绘制图表,提供了多种绘图函数和样式设置选项。
sklearn.linear_model.Perceptron:感知机模型。
sklearn.model_selection.train_test_split:用于将数据集划分成训练集和测试集。
sklearn.model_selection.GridSearchCV:用于对模型进行参数调优。
sklearn.neural_network.MLPClassifier:多层感知机分类器。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neural_network import MLPClassifier
plt.rcParams['font.sans-serif'] = ['Times New Roman'] # 设置字体
# 读取数据集
file = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class'] # 指定列名
df = pd.read_csv(file, names=names)
# 将类别为Iris-virginica的行删除
df = df[df['class'] != 'Iris-virginica']
# 将类别映射为1和-1
df['class'] = df['class'].map({"Iris-setosa": 1, "Iris-versicolor": -1})
# 数据集分割
x_train, x_test, y_train, y_test = train_test_split(df[['sepal_length', 'petal_length']], df['class'], train_size=0.8)
# 初始化感知机模型
# fit_intercept=True 表示模型拟合时会自动计算截距(即偏置项),而 max_iter=1000 则指定了训练过程中的最大迭代次数。
model = Perceptron(fit_intercept=True, max_iter=1000)
# 训练模型
model.fit(x_train.values, y_train.values)
# 计算模型的准确率
score = model.score(x_test.values, y_test.values)
print("斜率:", model.coef_)
print("截距:", model.intercept_)
print("分类的精准度为:", score)
# 绘制分类边界
# plt.figure创建绘图对象,参数figsize设置图片的宽度和高度
fig = plt.figure(figsize=(5, 5))
fig.set_dpi(600) # 设置高dpi使得图像在放大后依然清晰
x_min, x_max = x_train['sepal_length'].min() - 1, x_train[
'sepal_length'].max() + 1 # x_train['sepal_length'].min() - 1 计算出了该特征的最小值减去1的结果,即 x 轴坐标的最小值。同样地,x_train['sepal_length'].max() + 1 计算出了该特征的最大值加上1的结果,即 x 轴坐标的最大值。这样计算出来的 x_min 和 x_max 分别是 x 轴坐标的最小值和最大值。这两个值可以被用来设置横轴的范围,从而保证绘制出来的图形中覆盖了所有的数据点。
y_min, y_max = x_train['petal_length'].min() - 1, x_train['petal_length'].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max,
0.01)) # np.arange(x_min, x_max, 0.01) 和 np.arange(y_min, y_max, 0.01) 分别生成了以0.01为步长的一系列坐标值,用于表示 x 和 y 轴上的所有可能取值。xx 和 yy 分别代表了基于这些坐标值生成的网格点矩阵。
# np.c_[xx.ravel(), yy.ravel()] 是将 xx 和 yy 的元素按照行展平,并以列的方式进行连接,生成一个新的二维数组。然后通过 dict() 函数将这个二维数组转换为字典。
# model.predict则直接带哦用感知机模型对数据进行分类
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
# Z.reshape(xx.shape) 将一维数组 Z 变形为一个形状与 xx 相同的二维数组,其中的每个元素表示对应网格点的预测结果。
Z = Z.reshape(xx.shape)
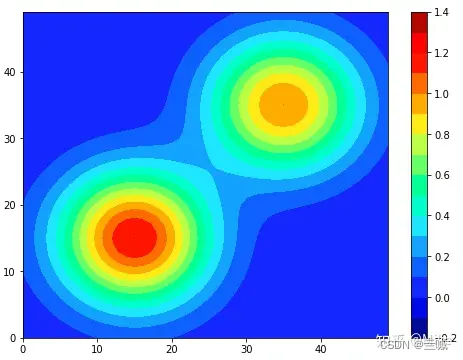
plt.contourf(xx, yy, Z, alpha=0.3, cmap='coolwarm') # 在 (xx, yy) 网格点上绘制一个颜色填充的等高线图,其中填充的颜色根据预测结果 Z 的值进行映射,透明度为 0.3。
plt.scatter(x_train['sepal_length'], x_train['petal_length'], c=y_train, cmap='coolwarm', edgecolors='k', marker='o',
s=80) # 以花萼长度为 x 轴,以花瓣长度为 y 轴的坐标系上绘制散点图,其中散点的颜色根据标签 y_train 进行映射,使用 'coolwarm' 颜色映射方式,散点的边界颜色为黑色,标记形状为圆形,大小为 80。
plt.title('Binary classification of Iris dataset',
y=-0.2) # 设置图表的标题,其中标题内容为 'Binary classification of Iris dataset',参数 y 用于控制标题的垂直位置,它的取值范围为 [0, 1],其中 0 表示标题靠近底部,1 表示标题靠近顶部。具体来说,y=-0.2 的意思是将标题向下移动 0.2 的高度,相当于将标题位置相对于图表的高度向下偏移了 20%。
plt.xlabel('sepal_length')
plt.ylabel('sepal_width')
plt.arrow(7.5, 0.45, -1 * np.pi / 2, 1.87,
width=0.1) # 用于在 Matplotlib 中绘制箭头,(7.5, 0.45)表示箭头的起始坐标,-1 * np.pi:箭头在 x 方向上的偏移量,即箭头的终点 x 坐标减去起始点 x 坐标。1.87:表示箭头在 y 方向上的偏移量,即箭头的终点 y 坐标减去起始点 y 坐标。width=0.1:表示箭头的宽度
fig.text(x=0.5, y=0.45, s='Decision Boundary') # x:文本的 x 坐标。y:文本的 y 坐标。s:要显示的文本内容。
plt.show()
# 绘制二分类图
df1, df2 = df.groupby(by="class") # 用于按照指定的列或条件对数据进行分组。在你的代码中,by="class" 参数表示按照 "class" 列进行分组。
df_versicolor = df1[
1] # 之所以用df1[1]和df2[1]而不用df1[0]和df2[0]是因为:df1[0]=-1,df2[0]=1,也就是说第一列指代的是分组的类别,而我们只关心第二分组的内容,它包含了一系列数据:sepal_length、sepal_width、petal_length、petal_width、class,而这些才是我们所关心的
df_setosa = df2[1]
fig = plt.figure(figsize=(5, 5))
fig.set_dpi(600)
plt.scatter(df_setosa["sepal_length"], df_setosa["petal_length"], label=+1)
plt.scatter(df_versicolor["sepal_length"], df_versicolor["petal_length"], marker="X", color="red",
label=-1) # 创建散点图,以(df_versicolor["sepal_length"], df_versicolor["petal_length"])为散点坐标值(x,y),marker="X" 表示将标记类型设置为 X,color="red" 表示将标记颜色设置为红色,而 label=-1 则是设置散点图的标签,可以用于图例显示。
line_Y = -1 * (df["sepal_length"] * model.coef_[0][0] + model.intercept_) / model.coef_[0][
1] # 根据线性模型的一般形式 y = wx + b,可以将 x 替换为 df["sepal_length"],然后通过 -1 * (df["sepal_length"] * model.coef_[0][0] + model.intercept_) / model.coef_[0][1] 计算出对应的 y 值,即决策边界的位置。累乘
plt.plot(df["sepal_length"], line_Y, c='black') # 绘制一条以(df["sepal_length"], line_Y)为(x,y)的直线,c='black' 表示将直线颜色设置为黑色
fig.text(x=0.5, y=0.4, s='Decision Boundary')
plt.legend() # plt.legend() 表示添加图例到当前的图表中。在这里,图例的标签和样式已经在前面的代码中设置好了,因此 plt.legend() 只需要调用就可以自动添加图例到图表中。
plt.ylabel("petal_length")
plt.xlabel("speal_length")
plt.show()
# 模型调参
clf = MLPClassifier(max_iter=10000) # 创建了一个多层感知器分类器对象,并设置了最大迭代次数
# 这段代码定义了一个参数网格param_grid,是一个字典,包含两个键值对。
# 第一个键是 "activation",对应的值是一个包含了四种激活函数选项的列表:["identity", "logistic", "tanh", "relu"]。这些激活函数分别是恒等函数、逻辑斯蒂函数、双曲正切函数和修正线性单元函数,用于定义神经网络中每个神经元的输出。
# 第二个键是 "hidden_layer_sizes",对应的值是一个从 3 到 4 的整数列表。这些整数代表了神经网络的隐藏层大小/宽度,即隐藏层中神经元的数量。
param_grid = {"activation": ["identity", "logistic", "tanh", "relu"], "hidden_layer_sizes": list(range(3, 5))}
GS_model = GridSearchCV(clf, param_grid,
cv=3) # GridSearchCV进行网格搜索交叉验证(Grid Search Cross-Validation)来帮助选择模型的最佳参数。GridSearchCV是scikit-learn库中的一个函数,它通过穷举搜索给定的参数组合来找到最佳的参数设置。它接收三个主要参数:评估模型性能的分类器(clf),参数网格(param_grid),和交叉验证的折数(cv)。
GS_model.fit(x_train, y_train)
print(f'模型的最优参数最优配置为{GS_model.best_params_},且训练精度为{GS_model.best_score_:.3f}')
# 为什么要计算截距?
# 在线性模型中,除了考虑各个特征的权重外,还需要考虑一个常数项,这个常数项就是截距。截距可以理解为当所有特征都为零时,模型的输出值应该接近的目标值。
# 因为数据的特殊性,使得两类数据很好紧凑型分割,所以分类的精确度始终为一
# 关于使用plt.show()会阻塞进程的问题:
# 当使用 plt.show() 函数来显示图形时,该函数会阻塞程序的执行,直到用户关闭图形窗口为止。在调用 plt.show() 后的代码将不会执行,除非用户关闭了图形窗口,程序才会继续往下执行。
# 因此,如果需要在显示图形之后继续执行代码,可以将 plt.show() 放在代码的最后部分,或者在需要显示图形的地方单独调用。
# 另外,如果希望以非阻塞的方式显示图形,可以考虑使用交互式的显示方式,例如在 Jupyter Notebook 等环境中,可以使用 %matplotlib inline 或 %matplotlib notebook 这样的魔术命令来实现非阻塞显示,并且在代码后继续进行交互和执行。
# 感知机和多层感知机
# 感知机是一种简单的线性分类模型,仅适用于线性可分问题。
# 多层感知机是一种多层、非线性的神经网络模型,具有更强大的学习能力,可以处理更复杂的非线性模式。

等高线图张这个样:
原文地址:https://blog.csdn.net/m0_64799907/article/details/134701592
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_9235.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
主题授权提示:请在后台主题设置-主题授权-激活主题的正版授权,授权购买:RiTheme官网
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。