重点介绍了Redis的LRU与LFU算法实现,并分析总结了两种算法的实现效果以及存在的问题。
一、前言
Redis是一款基于内存的高性能NoSQL数据库,数据都缓存在内存里, 这使得Redis可以每秒轻松地处理数万的读写请求。
相对于磁盘的容量,内存的空间一般都是有限的,为了避免Redis耗尽宿主机的内存空间,Redis内部实现了一套复杂的缓存淘汰策略来管控内存使用量。
Redis 4.0版本开始就提供了8种内存淘汰策略,其中4种都是基于LRU或LFU算法实现的,本文就这两种算法的Redis实现进行了详细的介绍,并阐述其优劣特性。
二、Redis的LRU实现
在介绍Redis LRU算法实现之前,我们先简单介绍一下原生的LRU算法。
2.1 LRU算法原理
LRU(The Least Recently Used)是最经典的一款缓存淘汰算法,其原理是 :如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很低,当数据所占据的空间达到一定阈值时,这个最少被访问的数据将被淘汰掉。
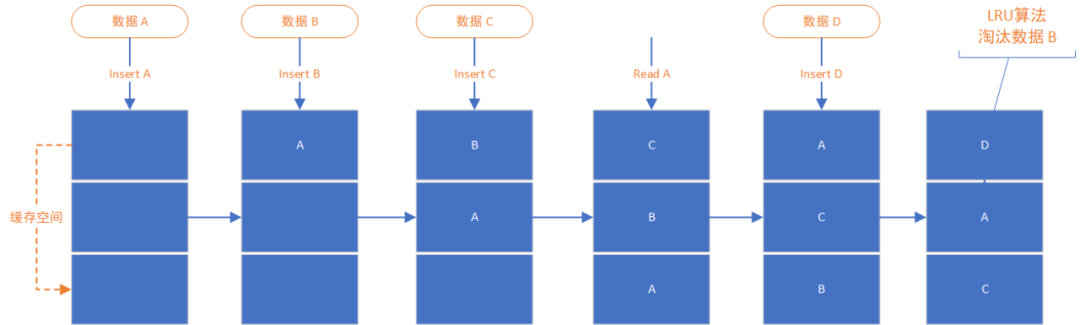
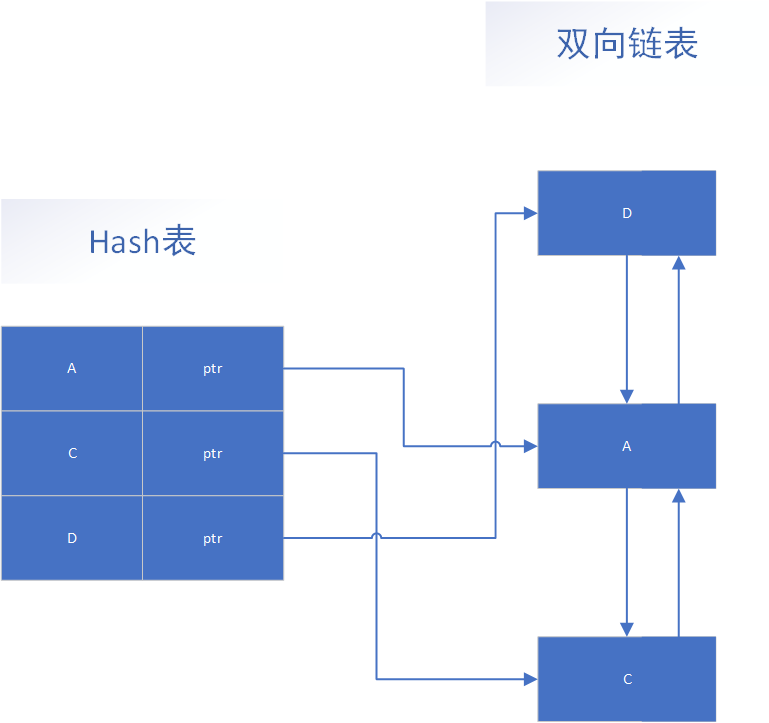
2.2 Redis LRU算法实现
2.3 LRU算法缺陷
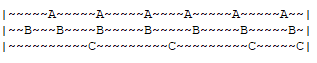
三、Redis的LFU实现
3.1 LFU算法原理
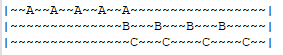
3.2 Redis LFU算法实现
3.2.1 LFU算法代码实现


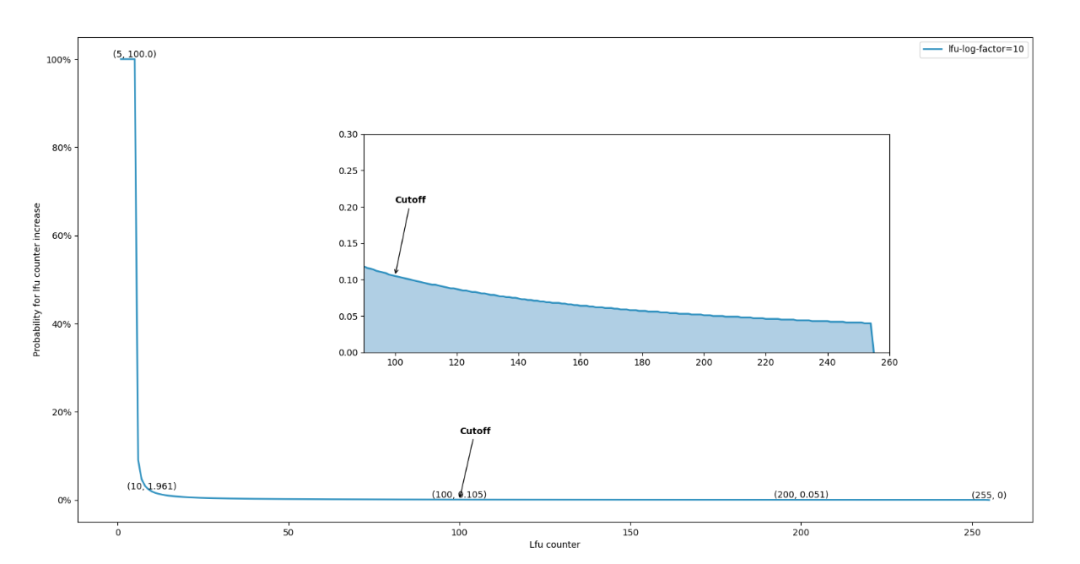
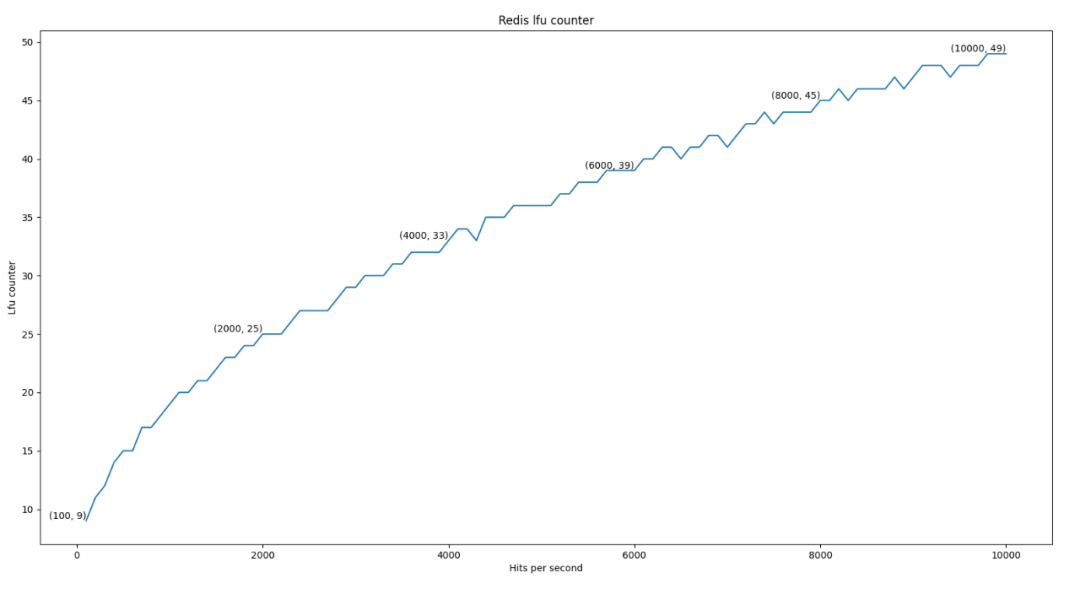
3.3.2 LFU Counter分析
四、总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







