本文介绍: 本博主将用CSDN记录软件开发求学之路上亲身所得与所学的心得与知识,有兴趣的小伙伴可以关注博主!也许一个人独行,可以走的很快,但是一群人结伴而行,才能走的更远!什么是聚合函数聚合函数作用于一组数据,并对一组数据返回一个值。聚合函数类型AVG()SUM()MAX()MIN()COUNT()聚合函数语法聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
前言
一、聚合函数介绍


聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
1、AVG和SUM函数

2、 MIN和MAX函数

3、COUNT函数

二、GROUP BY
1、基本使用
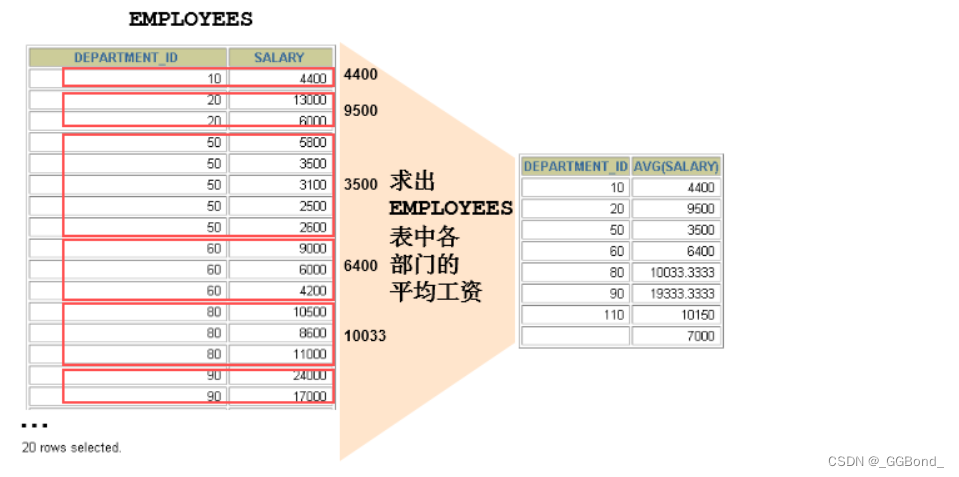
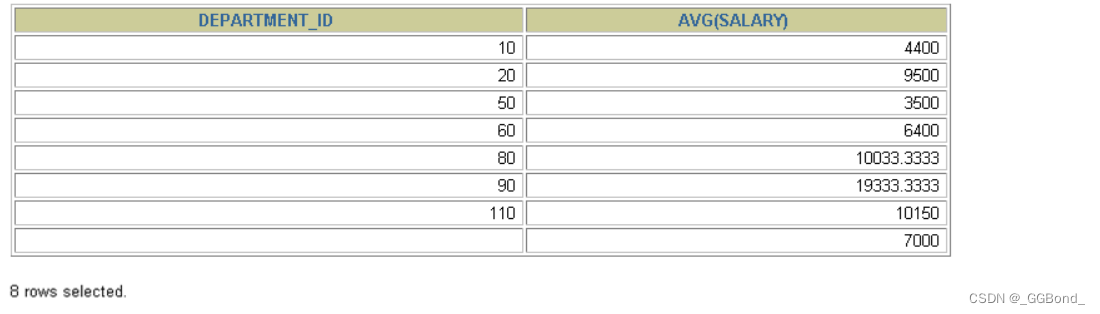
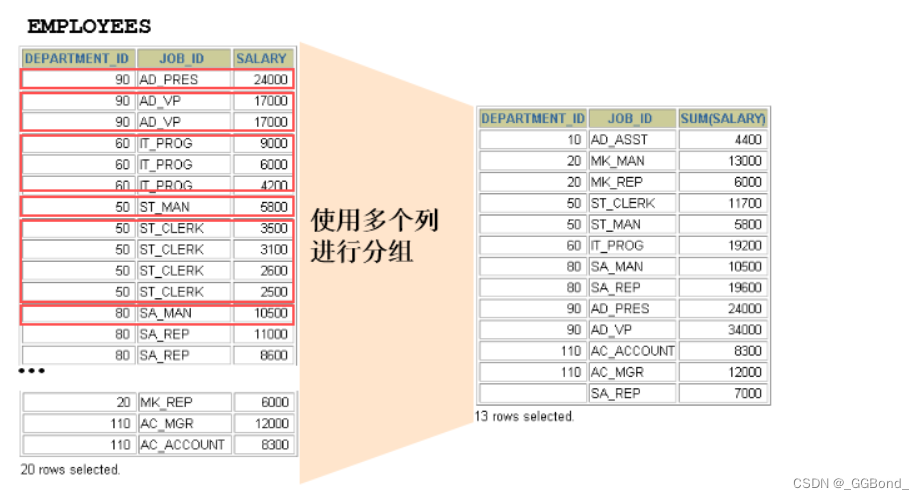
2、使用多个列分组
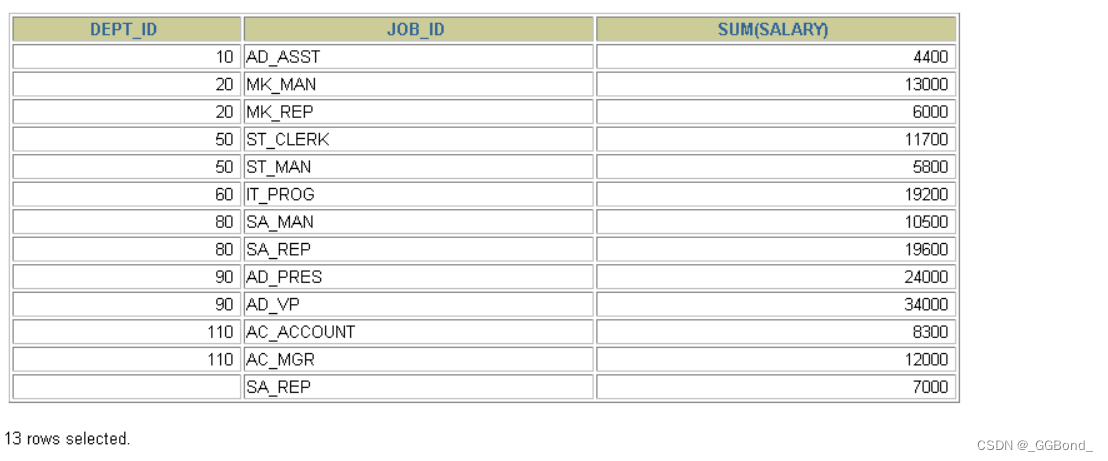
3、 GROUP BY中使用WITH ROLLUP
三、HAVING
1、基本使用
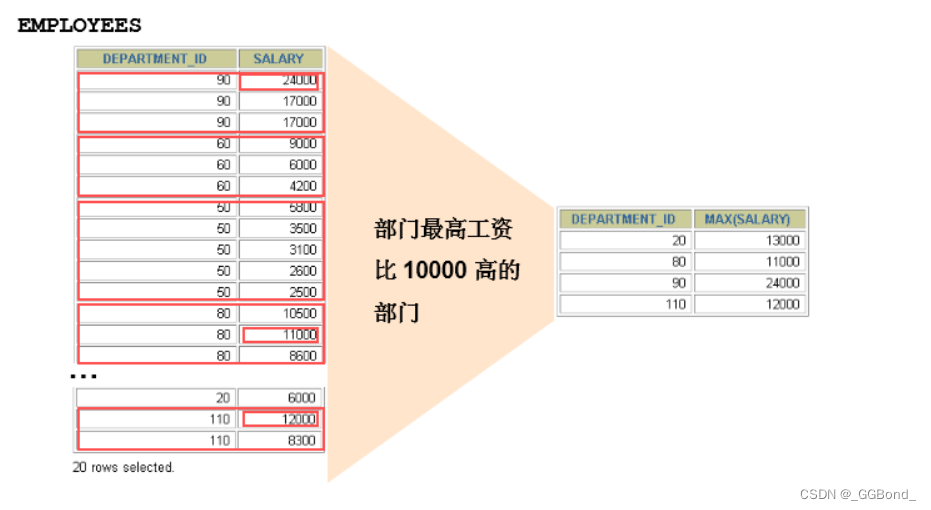



2、WHERE和HAVING的对比
四、 SELECT的执行过程
1、查询的结构
2、SELECT执行顺序

3、SQL 的执行原理
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





