本文介绍: 通过第一张表emp中的 员工FORD, 找到对应的领导编号,正好对应第二张emp表的员工编号。对stu表和exam表联合查询,把所有的成绩都显示出来,即使这个成绩没有学生与它对应,也要。查询和10号部门的工作岗位相同雇员的名字、岗位、工资、部门号 ,但是不包含10号自己的。寻找到emp表的部门号 与 tmp表的部门号 相同的 数据 才是合适的,所以加上。左侧的表按条件拼接(条件满足拼接,条件不满足拼NULL) 右侧表完全显示。左侧表完全显示 右侧的表按条件拼接(条件满足拼接,条件不满足拼NULL)
1. 复合查询
多表笛卡尔积
显示雇员名、雇员工资以及所在部门的名字
由于员工 信息属于 emp表 而所在部门名字属于 dept表
数据来自不同的表,所以需要进行多表查询

表示从 emp (员工表) 和dept (部门表) 中获取信息




自连接

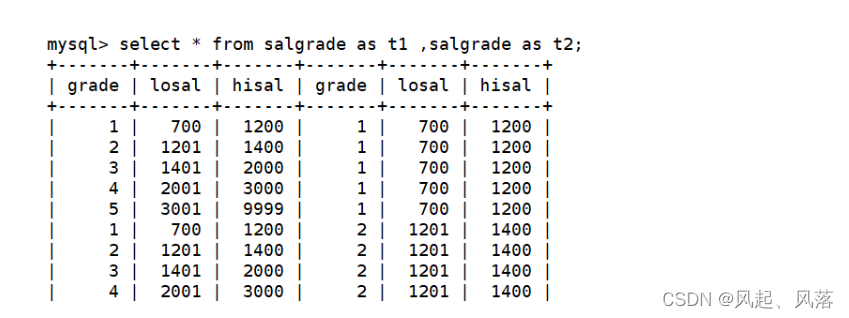

在where子句使用子查询
单行子查询

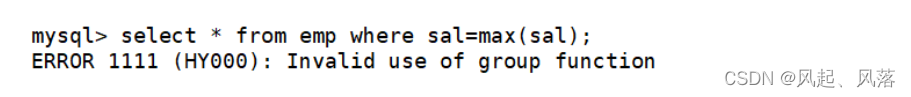
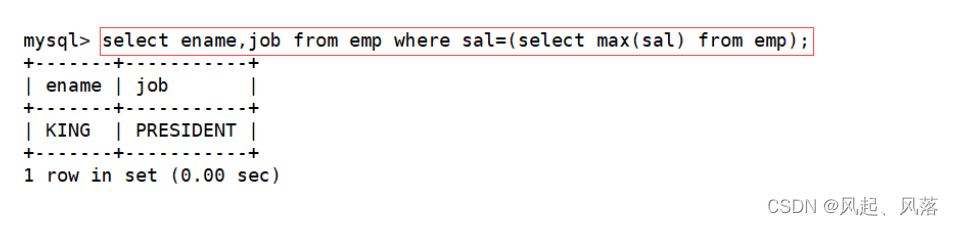
多行子查询
in关键字



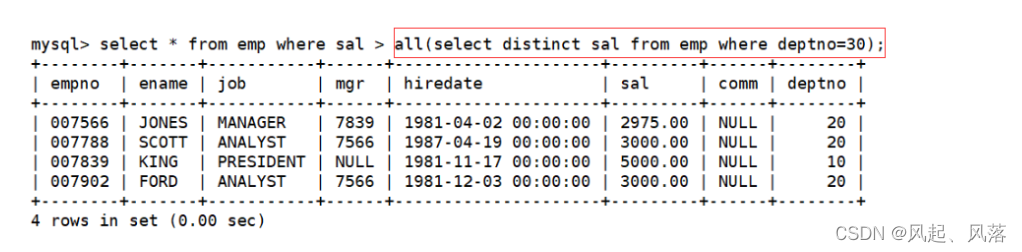
all关键字

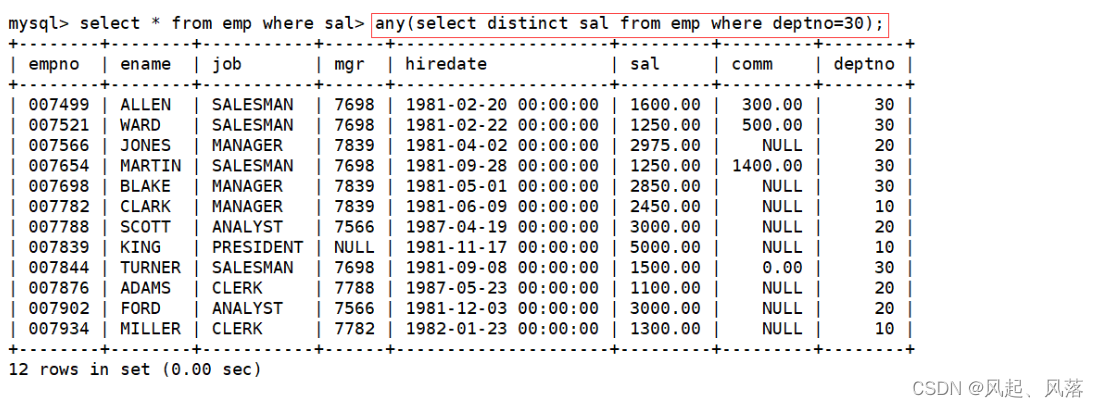
any关键字

多列子查询



在from子句中使用子查询




合并查询
union



union all

2. 内连接
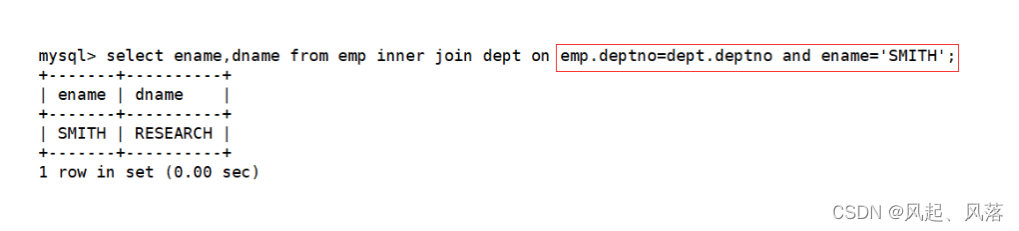
3. 外连接
左外连接






右外连接


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。