本文介绍: Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。Elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。Elasticsearch是。
一.什么是Elasticsearch?
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
Elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
Elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
Elasticsearch是elastic stack的核心(不可替换),负责存储、搜索、分析数据。

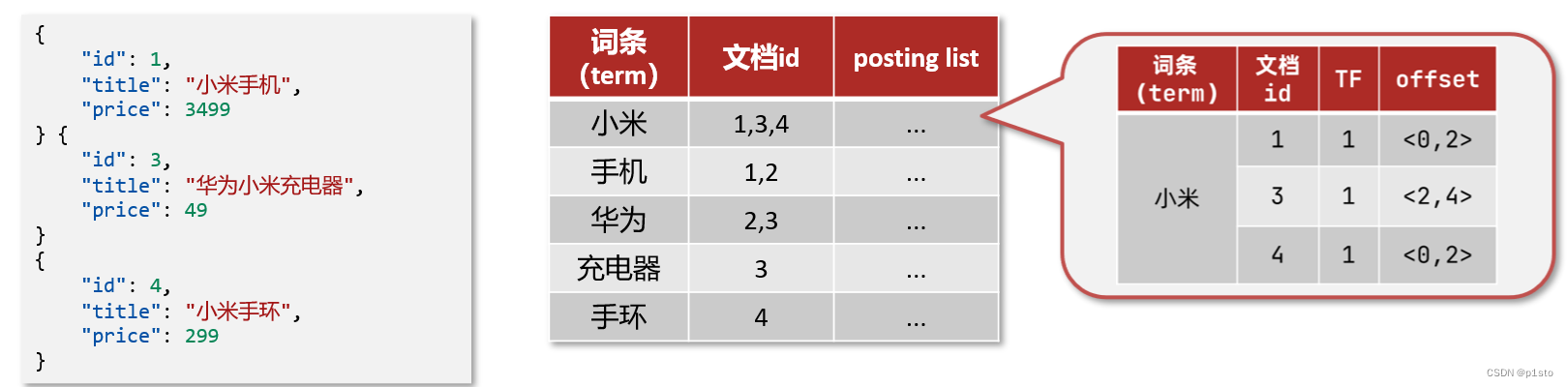
1.正向索引和倒排索引

2.Mysql和ES的概念对比

3.安装elasticsearch、kibana
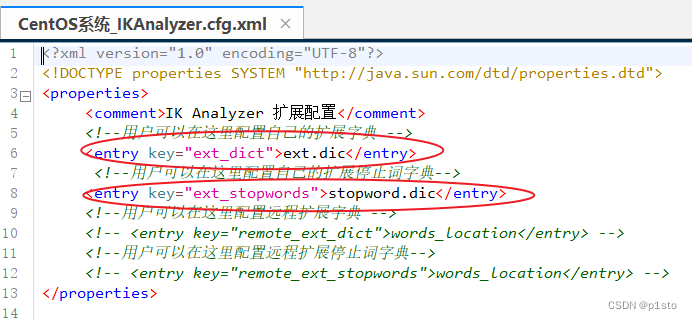
二.IK分词器
三.索引库操作
四.文档操作
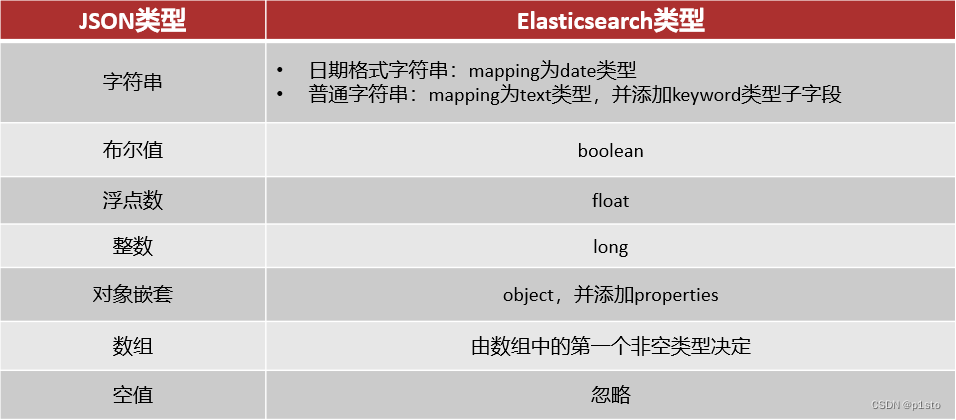
五.RestClient操作索引库
1.初始化RestClient
2.创建索引库
3.删除索引库
4.判断索引库是否存在
六.RestClient操作文档
1.新增文档
2.查询数据
3.修改数据
4.删除数据
5.批量插入数据
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。