一、什么是数据库和缓存双写一致性?
在分布式系统中,数据库和缓存会搭配一起使用,以此来保证程序的整体查询性能。也就说,分布式系统为了缓解数据库查询的压力,会将查出来的数据保存在缓存中,下次再查询时,直接走缓存系统,而不再查询数据库,这样就极大的提高了整体的查询性能。
1.1 为什么缓存比数据库快?
缓存之所以比数据库快的主要原因有以下 3 点:
-
内存访问速度快:缓存通常将数据存储在内存中,而数据库将数据存储在磁盘上。相比于磁盘访问,内存访问速度更快,可以达到纳秒级别的读取速度,远远快于数据库的毫秒级别的读取速度。
-
IO 操作次数少:数据库通常需要进行磁盘 IO 操作,包括读取和写入磁盘数据。而缓存将数据存储在内存中,避免了磁盘 IO 的开销。内存访问不需要进行磁盘寻址和机械运动,相对来说速度更快。
-
特殊的数据结构:缓存的数据结构通常为 key–value 形式的,也就是说缓存可以做到任何数据量级下的查询数据复杂度为 O(1),所以它的查询效率是非常高的;而数据库采用的是传统数据结构设计,可能需要查询二叉树、或全文搜索、或回表查询等操作,所以其查询性能是远低于缓存系统的。
1.2 缓存一致性问题
虽然缓存可以极大的提高查询性能,但同时也带来的新的问题:数据库和缓存一致性的问题。
具体来说,在一个常见的应用场景中,当更新数据库的操作完成后,需要同步更新缓存,以保证缓存中的数据与数据库中的数据保持一致。然而,由于数据库和缓存是两个不同的组件,它们的数据更新操作是异步的,可能存在以下问题:
-
数据延迟:数据库更新和缓存更新之间存在时间延迟,导致缓存中的数据不是最新的。这可能会引起数据的不一致,当其他请求读取数据时,可能会读取到旧的数据。
-
更新失败:在尝试更新缓存时,可能出现更新失败的情况。例如,缓存节点暂时不可用,网络故障等。如果更新缓存失败而未进行适当的处理,也会导致数据库和缓存之间的数据不一致。
也就说,因为以上原因,可能会导致 A 用户和 B 用户执行了同一个查询操作,但是得到了完全不同的结果,这就是数据库和缓存的一致性问题。
二、如何解决双写一致性问题?
然而,前 3 种解决方案,有同一个问题,也就是当第一步操作执行完之后,第二步未执行的情况下,就会导致数据库和缓存的一致性问题,例如第一步执行完之后,系统掉电了,那么一致性问题就会一直存在。
相比之下,第 4 种解决方案(先删除缓存,后修改数据库)相比于前三种解决方案更有优势,起码它保证了双方都未执行成功,那么从数据一致性层面来讲,第 4 种方案起码保证了一定的数据一致性,然而第 4 种执行方案依然存在其他问题,例如以下这几个:
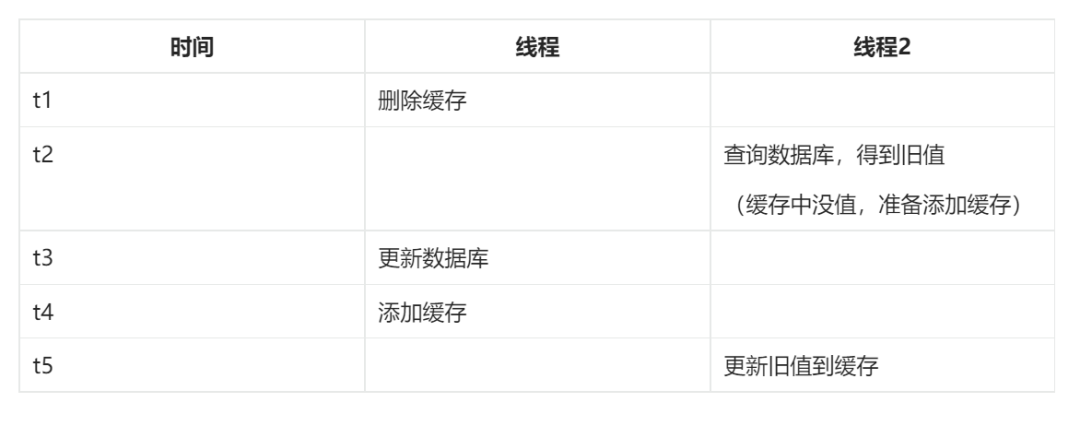
三、消息队列 + 延迟双删策略
3.1 为什么要使用消息队列?
因为消息队列里面有消息确认机制,它可以保证我们执行完第一步之后,即时掉电重启的情况,依然可以执行后续的流程,因为之前的消息,未进行消息确认,所以程序重启之后,会继续执行后续的流程,这样就保证了业务执行的完整性。
3.2 什么是延迟双删?
延迟双删指的是删除两次缓存(并且最后一次是延迟删除),具体执行流程如下:
-
删除缓存
-
更新数据库
-
延迟一会再删除缓存
最后一次延迟删除缓存的原因是,为了避免上面因为并发问题导致保存旧值的情况发生,所以会延迟一段时间之后再进行删除操作。这样即使有并发问题,也能最大限度的解决保存旧值的情况,因为是延迟之后删除的,所以即使因为并发问题保存了旧值,但延迟一段时间之后旧值就会被删除,那么这样就自然而然的保证了数据库和缓存的最终一致性。
总结
数据库和缓存双写一致性问题是一道经典的面试题,最初解决方案是先更新数据库、再删除缓存,然而如果发生掉电情况,只执行了前一步操作,那么缓存和数据库就出现了不一致性的问题。为了解决这个问题,所以通常会采用延迟双删 + 消息队列来保证业务的完整执行和数据一致性问题。
原文地址:https://blog.csdn.net/CSDN2497242041/article/details/134684549
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_9479.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





