本文介绍: 常见的方式:hive里最常用的方式生成唯一id,就是直接使用 row_number() 来进行,这个对于小数据量是ok的,但是当数据量大的时候会导致,数据倾斜,因为最后生成全局唯一id的时候,这个任务是放在一个reduce里进行的,数据量过大会有很大的瓶颈。优化的方式:主体的思想就是先分再合,参考下一个思路:这个思路是借鉴了一篇文章的思路:附上链接:bitmap用户分群方法在贝壳DMP的实践和应用_架构_侯学博_InfoQ精选文章我是只想用sql来做具体的实现,如何实现最好
常见的方式:
hive里最常用的方式生成唯一id,就是直接使用 row_number() 来进行,这个对于小数据量是ok的,但是当数据量大的时候会导致,数据倾斜,因为最后生成全局唯一id的时候,这个任务是放在一个reduce里进行的,数据量过大会有很大的瓶颈。
优化的方式:
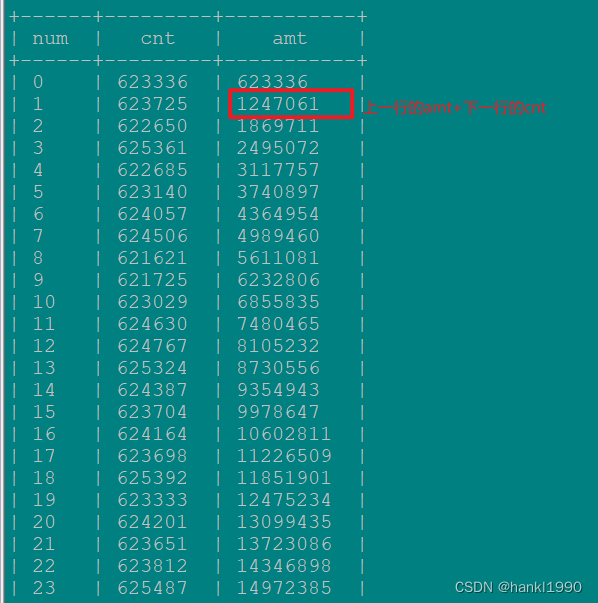
主体的思想就是先分再合,参考下一个思路:

这个思路是借鉴了一篇文章的思路:附上链接:bitmap用户分群方法在贝壳DMP的实践和应用_架构_侯学博_InfoQ精选文章
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。