准备工作
汇编基础
三种寻找源码的方式


alloc 方法的底层调用流程
追踪 alloc
实例化一个对象往往是通过[[xxx alloc] init],那么 alloc 和 init 的区别在哪?,将两个方法分开调用,并用 2 个指针引用
打断点控制输出 user1 和 user2 的内存地址,发现内存地址是一样的:

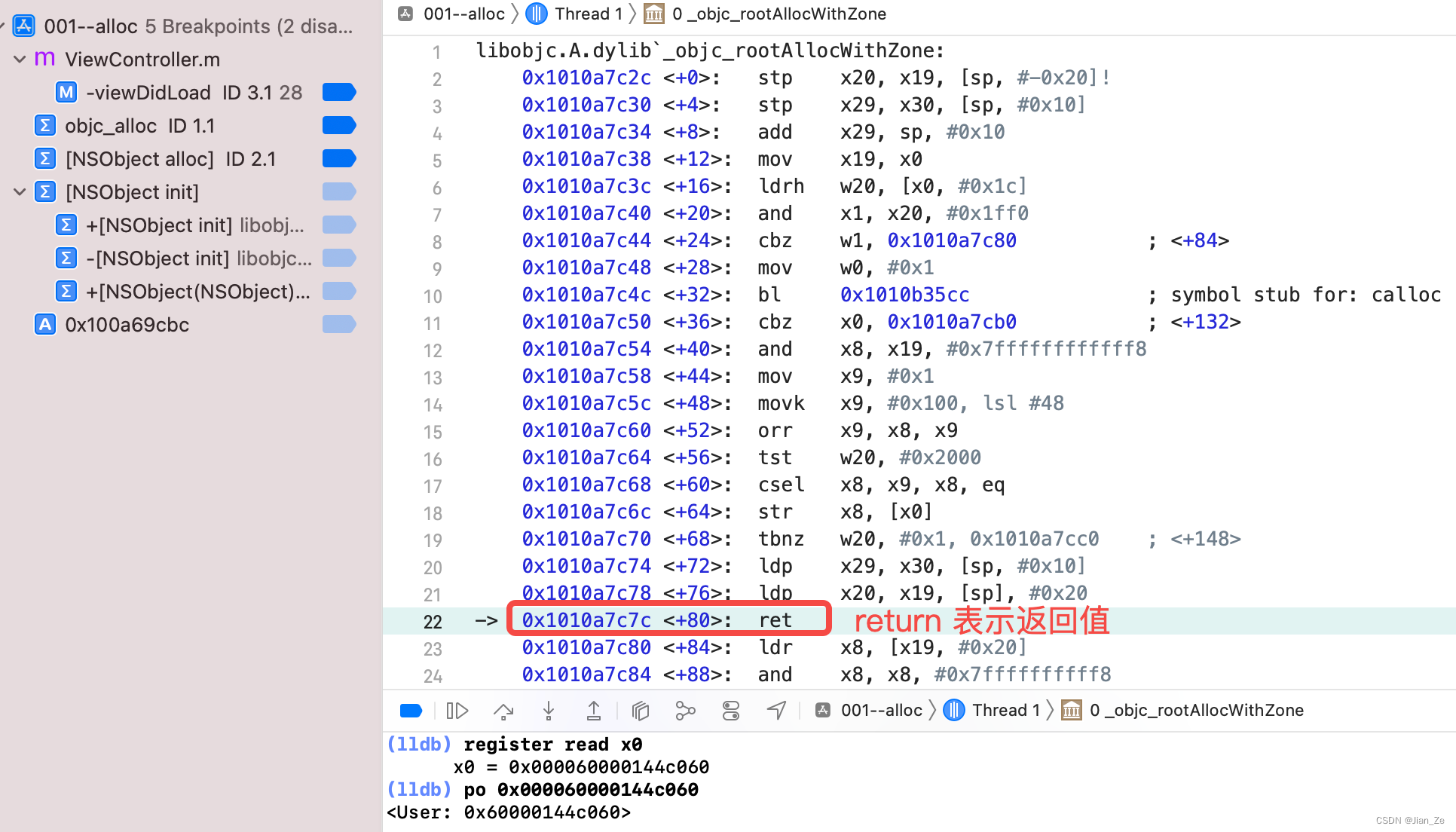
说明 init 方法不会去开辟内存空间。在 alloc 方法这行打上断点,开启汇编调试,运行代码(注意使用 control + step into,否则会跳过这行代码):
; symbol stub for: objc_alloc: 意思是该地址保存的是 objc_alloc 方法的符号。

查看 objc 源码(地址在附录),搜索 objc_alloc 发现,fixupMessageRef调用 alloc时,使用的实现是objc_alloc。(sel 代表方法名)

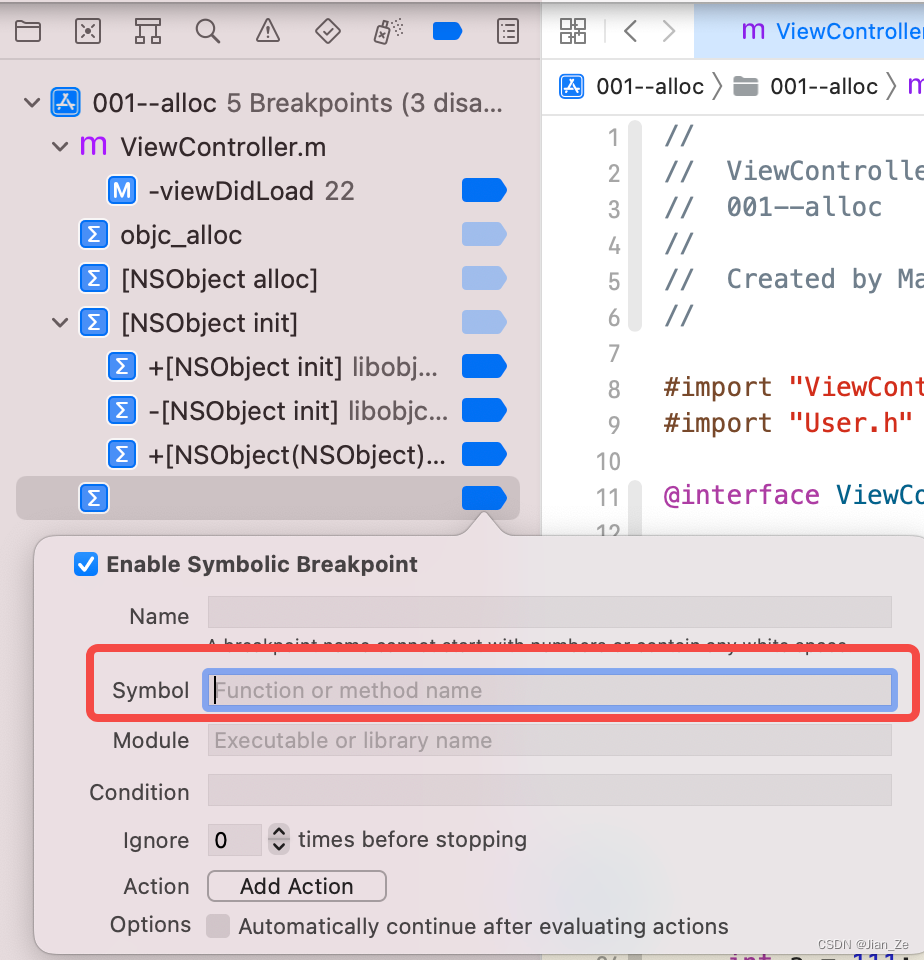
回到自己的项目添加一个 objc_alloc符号断点,再次调试 alloc 方法,发现跳过了_objc_rootAllocWithZone,直接到了objc_msgSend,先不管,打印一下寄存器 x0 和 x1,确实是 alloc 方法。
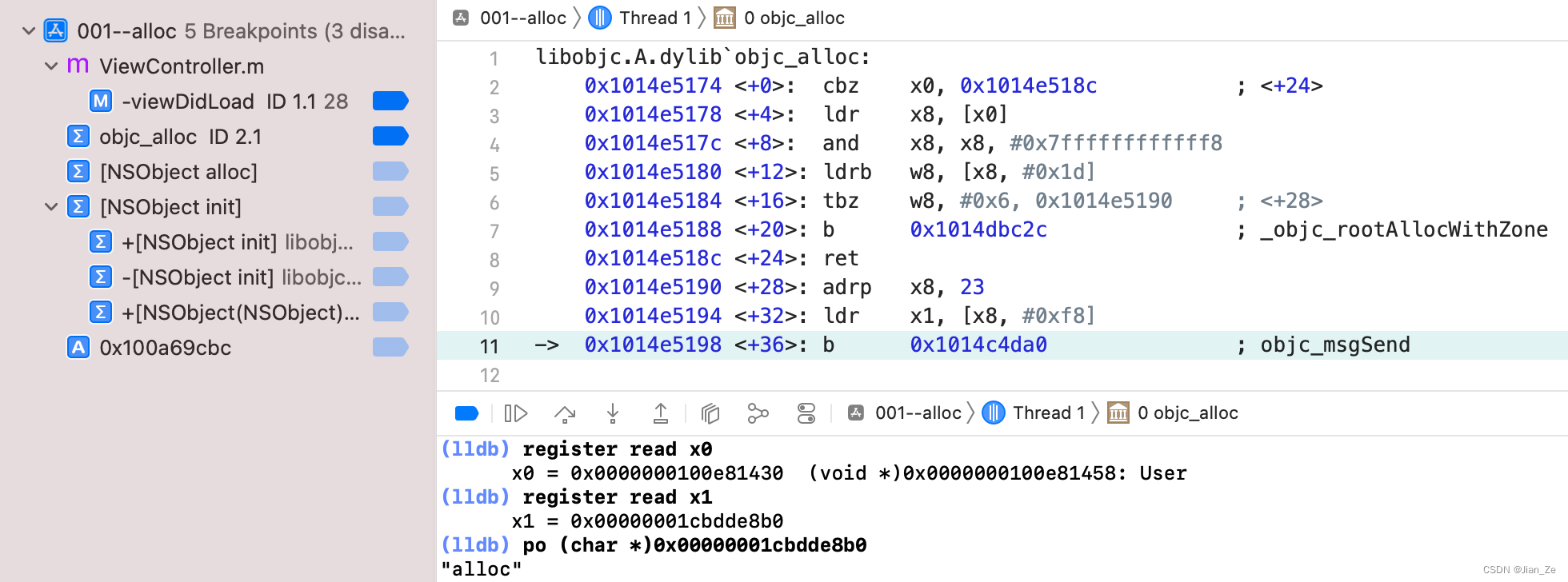

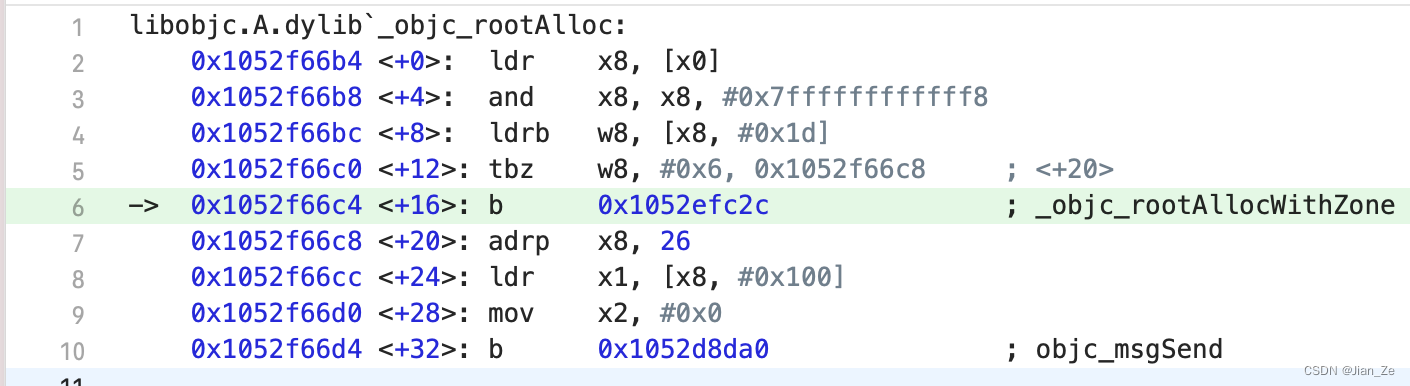


结论:
追踪 init
增加 init 方法的符号断点 [NSObject init],进入汇编调试:
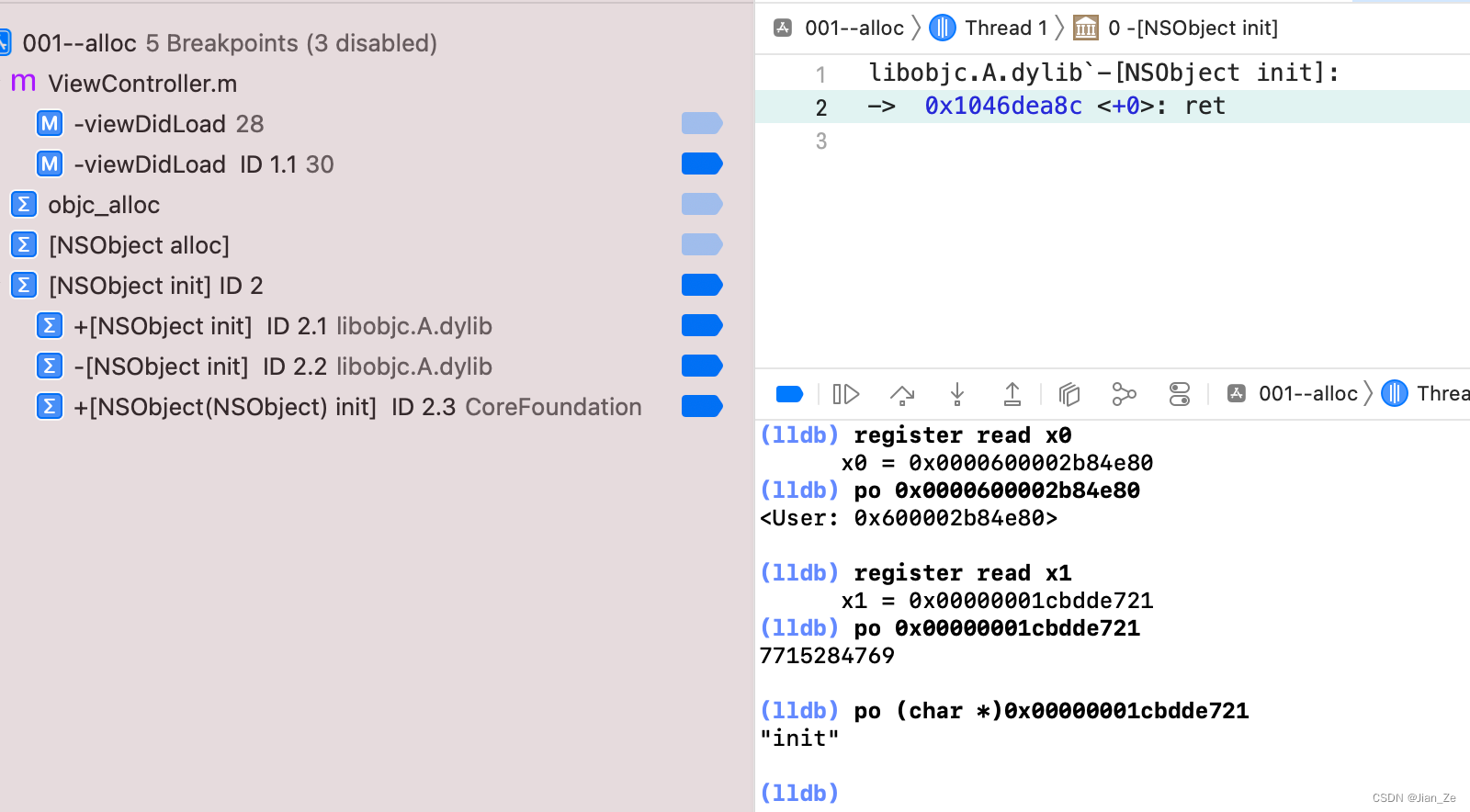
源码查找 init,_objc_rootInit 只是返回了 obj
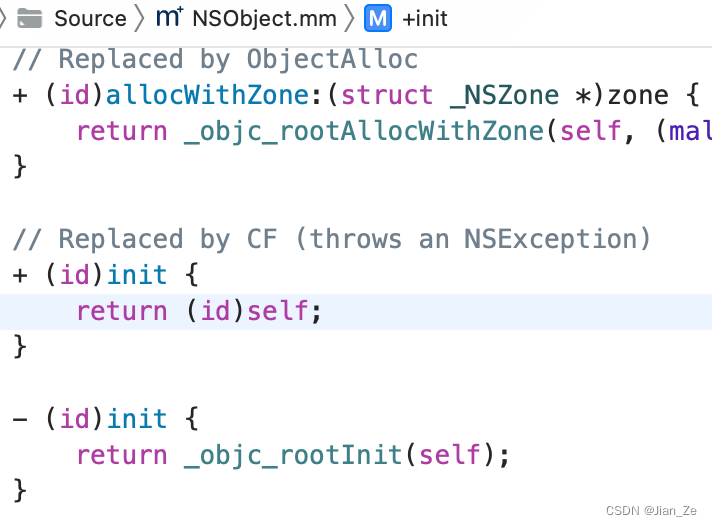
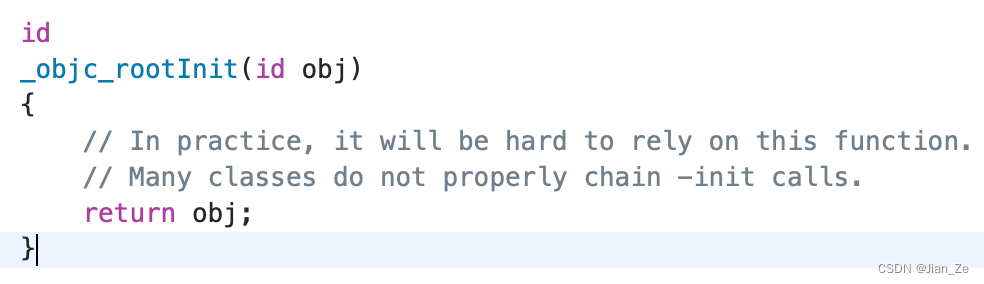
结论:
init 只是返回了自身, init 作为工厂方法,目的是让子类继承并重写。比如 NSArray 继承 NSObject, 重写了 init 方法。
追踪 new


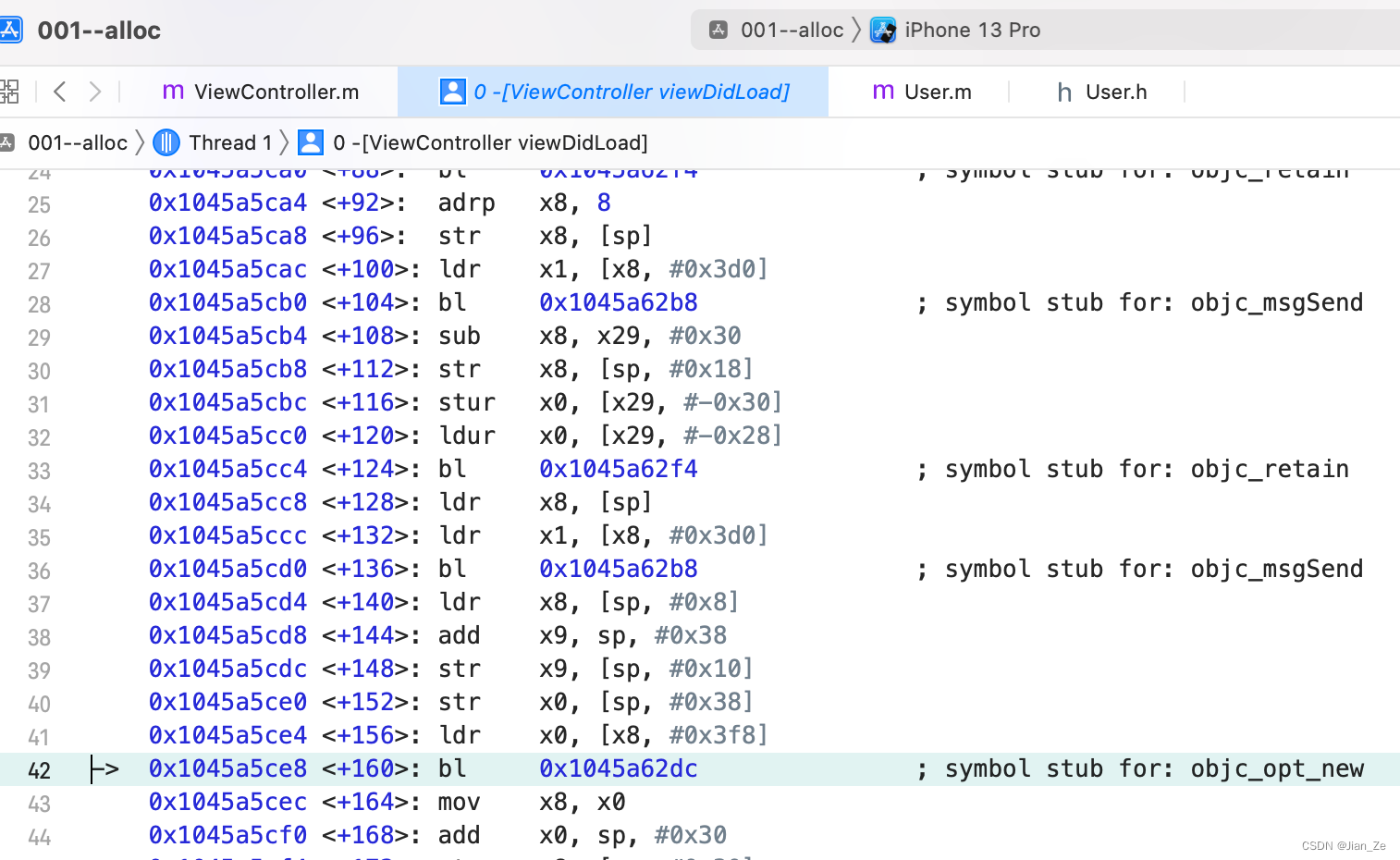
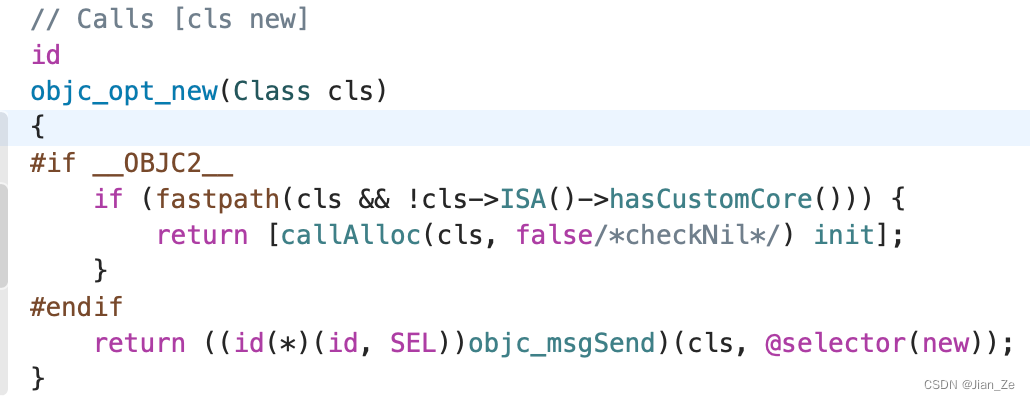
结论:new = alloc + init
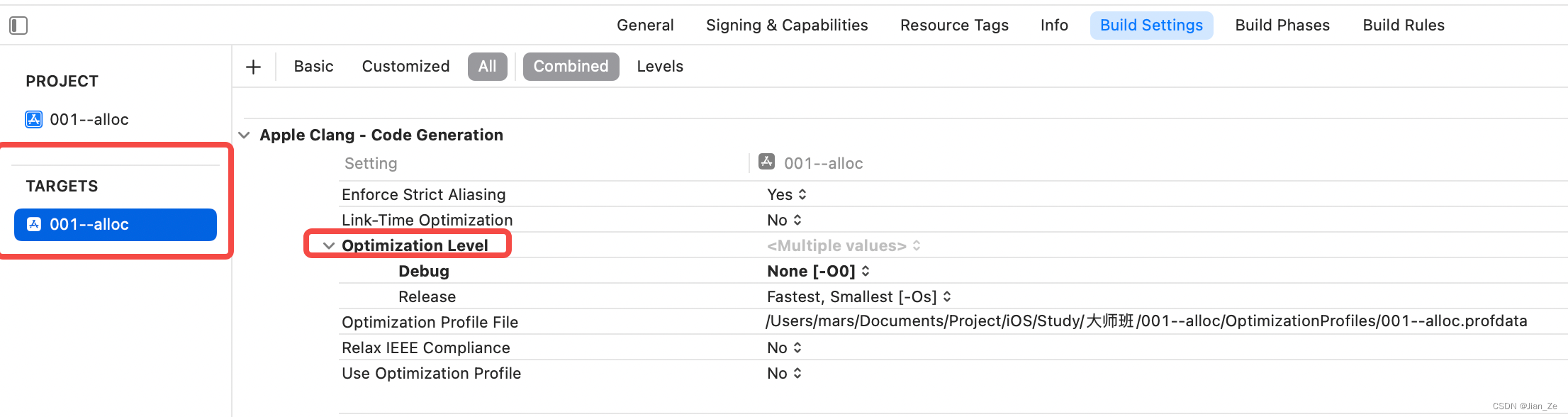
优化等级

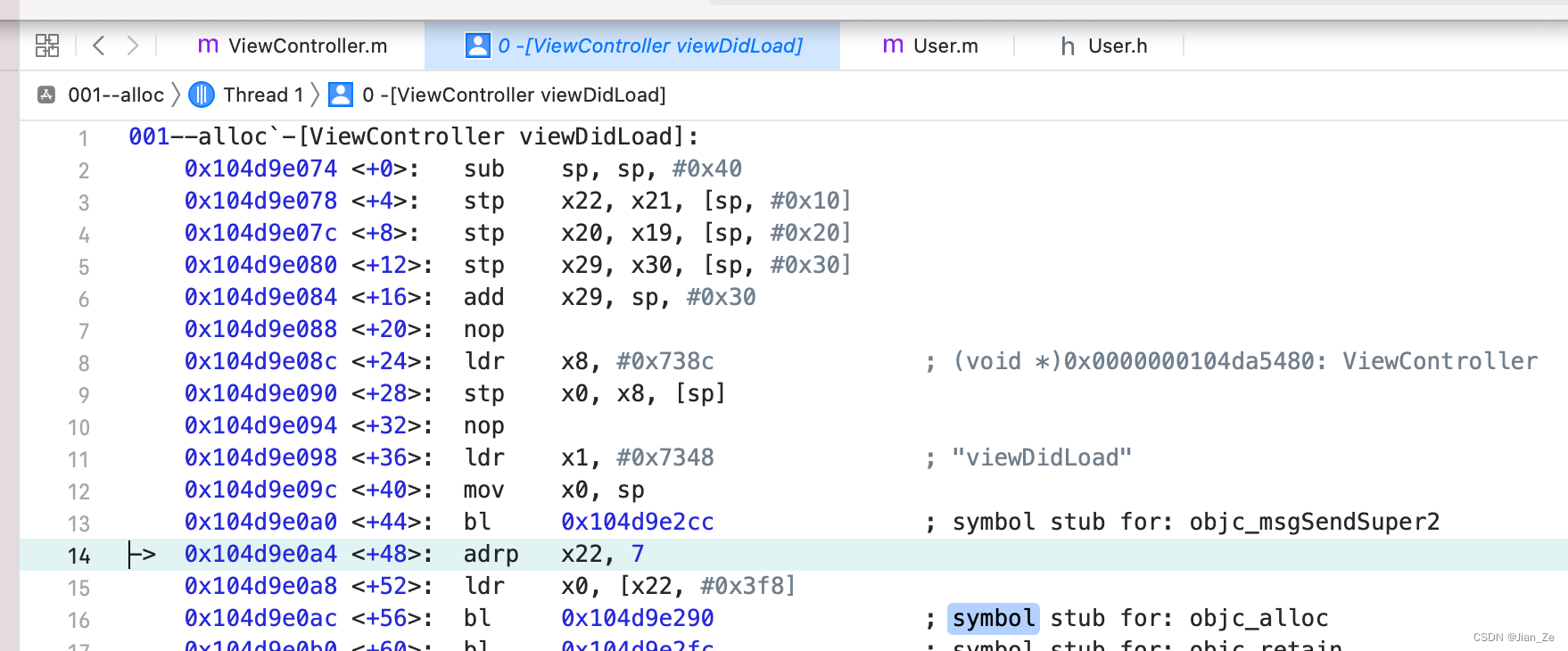



源码调试 alloc



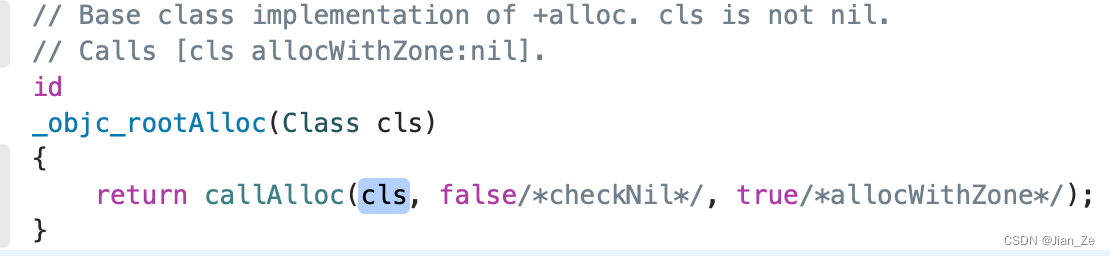

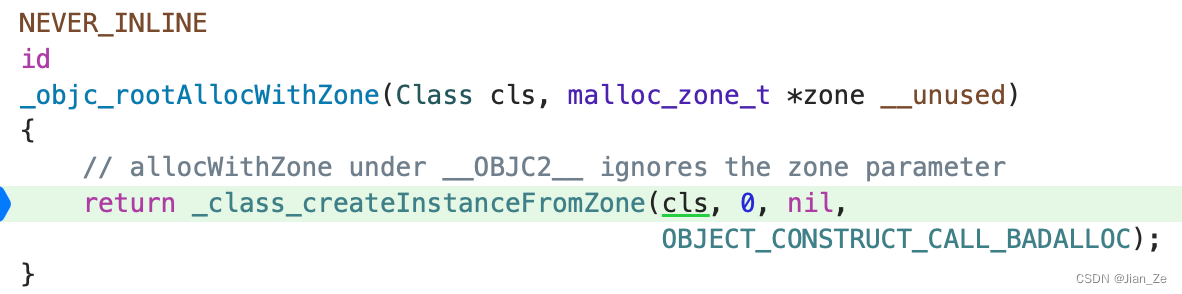

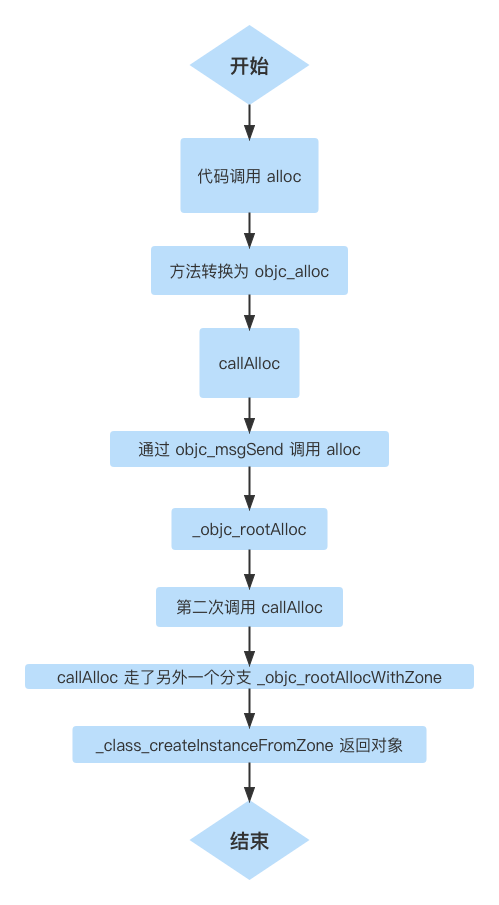
对象的创建


内存对齐


calloc


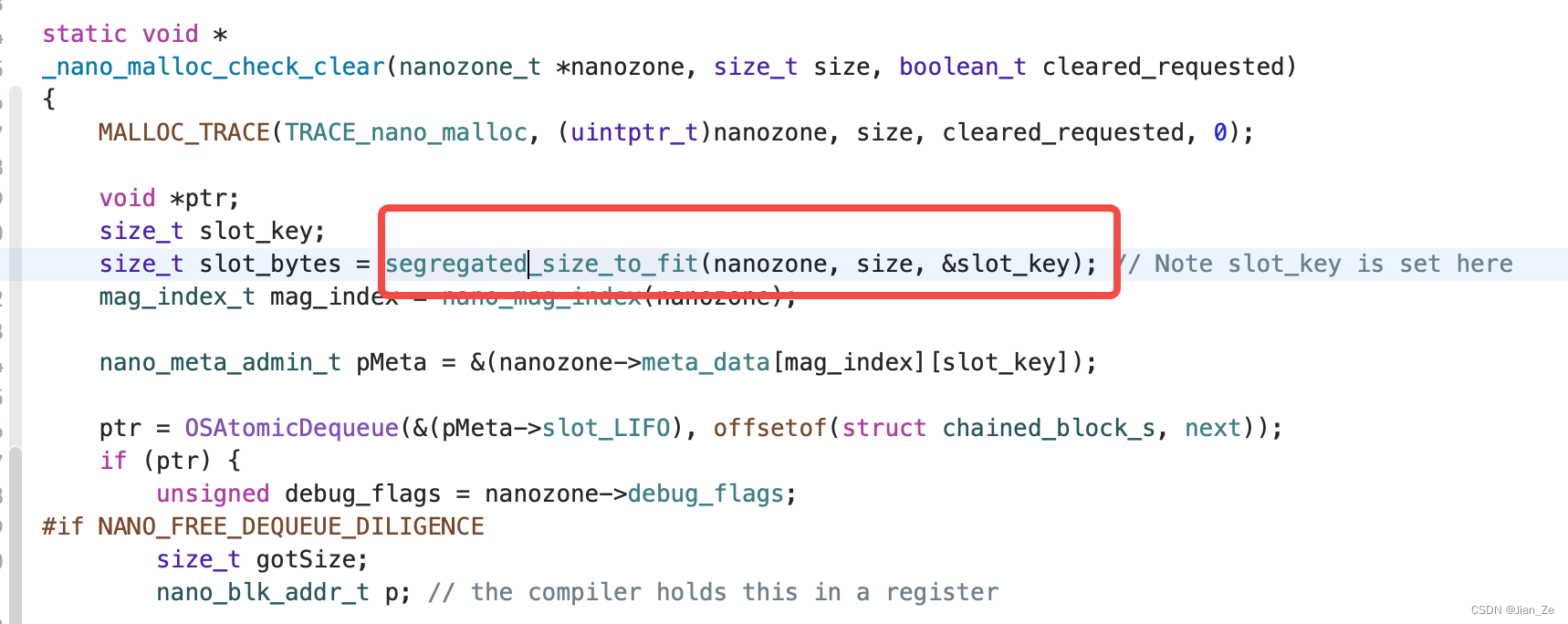
对象的本质


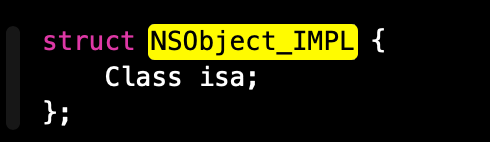
结构体的内存对齐方式
附录
objc 源码下载
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。